write by 九天雁翎(JTianLing) -- www.jtianling.com
讨论新闻组及文件
为什么选择Bullet
Bullet
算是一个比较流行的3D物理引擎了,大概的看了几眼以后,了解了一些基本用法,发现很多3D物理中的概念与2D(比如Box2d)中的概念是相同的,甚至,Bullet的一些用法都与Box2D类似。基本了解以后,对于我来说,那就是iPhone平台的问题了。
我选择Bullet而不是其它一大堆同样著名的物理引擎,主要源自乌龙(oolongengine
)
引擎,该引擎由wolfgang.engel最先创建,并且内嵌了bullet的支持,竟然如此大牛都青睐的引擎,我怎么能无视呢?何
况,oolongengine的使用,也说明Bullet在iPhone中使用完全没有问题。另外,还有Blender这个非常著名的3D建模工具也是对
Bullet有直接支持,可见Bullet的流行程度。事实上,还有些故事,比如oolongengine的项目负责人之一erwin.coumans,
同时就也是Bullet的项目创建者兼现在的负责人。(到Google
Code上去看看就知道了)并且,erwin提到,Bullet能够流畅的在iPhone上运行,wolfgang提供了很大的帮助,对浮点运算进行了特
别优化。最有意思的是,迪斯尼公司,自己的一些项目用到了Bullet,(看主页上的介绍,起码玩具总动员3这个游戏用到了Bullet)所以开发了自己
的MAYA
Bullet插件,为了回报开源社区,已经将此插件开源了。。。。。感谢Bullet,也感谢迪斯尼,同时感叹国外这种开源社区之间的交互。。。。。呵
呵,这才叫欣欣向荣的良性发展,你帮助我,我帮助你,公司受到帮助,也对社区进行回报。知道了这么多故事以后,更加是对Bullet多了很多好感。最值得
一提的是,erwin
简直就是个开源狂人。。。。。他还发起过一个叫做gamekit
的开源游戏引擎项目,希望整合Ogre/Irrlicht和Bullet,因为是erwin创建的项目,也非常值得期待。。。。。。。
闲话多说一向是我的毛病。。。。也就说到这里了,用以前的OGRE on iPhone
工程直接开工了。
在XCode中编译Bullet和OgreBullet
初下载Bullet后,用CMake做工程,只能做Mac OS
X的工程,没有iPhone的选项,于是参考一下乌龙引擎的做法,就是将整个Src目录都拷贝进自己的工程,好像是从iPhone开始,流行这种"暴力"
使用源代码的方式了。。。。。只能说Apple的XCode开发的还不足够人性化,所以建库的工程没有VS那么方便,再加上iPhone天生的不支持动态
库,更加助长了这种“暴力”使用源代码的方式,其实每次修改工程文件编译都会慢很多,无奈啊。。。。。在Bullet的论坛中,搜索到erwin的准官方解决方案
就是拷贝全部目录。。。。汗一个-_-!
既然如此,一切倒是简单了。。。。。下载Bullet的源码
,目前最新的是2.77,拷贝Src目录,删掉无用文件,比如CMake的一些文件。(或者直接从oolong引擎中将整个Bullet目录拷贝过来最简单,只不过版本目前是2.73)然后配置Bullet的Include目录,编译,一切OK。
现在开始尝试嵌入OgreBullet,方法还是直接包含源代码。比较特殊点的是OgreBullet需要用到Bullet的
ConvexDecomposition,这个库在Bullet的Extra中,也将源代码都拖过来,然后弄好include目录,就没有问题了。
测试
现在进入测试阶段,就用OgreBullet的Tutorial
中
的例子。源代码全部拷贝过来,唯一的问题是ExampleApplication在iPhone中有些小问题,修改一下函数,namespace后问题解
决。运行时崩溃,查看问题,还是ExampleApplication这个类的问题,难怪在Ogre的iPhone
template不用这个类,崩溃的地方很有意思,OIS获取键盘的时候:
mKeyboard = static_cast<OIS::Keyboard*>(mInputManager->createInputObject( OIS::OISKeyboard, bufferedKeys ));
注释更加有意思:
//Create all devices (We only catch joystick exceptions here, as, most people have Key/Mouse)
典型反映了代码永远赶不上时代变化,既然这个类已经不被人使用了,我也就不费劲去用了,将原来的例子代码全部嵌入到OgreFramework类中。
运行,崩溃,发现忘了添加新增的资源,将BumpyMetal.jpg材质和cube.mesh模型添加进工程。再次运行,一些正常,有图有真相:

当一切都OK以后,我发现我的目标竟然与GameKit是一样的。。。。。不就是Ogre+Bullet吗?erwin
估计以前就已经想过我所想了。。。。。也许,尝试下GameKit也不错。
原创文章作者保留版权 转载请注明原作者 并给出链接
write by 九天雁翎(JTianLing) -- www.jtianling.com
阅读全文....
write by 九天雁翎(JTianLing) -- www.jtianling.com
讨论新闻组及文件
准备
早就知道Bullet有个比较好的MAYA插件,那是迪斯尼自己的东西,然后开源的,在bullet的网站就有下载
。但是一直一来都是学习3D Max,接触了一下MAYA,感觉不是太习惯,有人说MAYA的操作方式接近设计师的思维。。。。我果然不是个设计师啊。。。。。我甚至都准备转投Blender了,好歹那也是开源免费的东西,而且与Bullet结合的还不错,还有GameKit这个好玩的东西在。我初步的看了一下,感觉GameKit有点类似LOVE这个Lua的2D游戏引擎,以一个数据包作为输入,然后是一个独立的可执行程序,只不过LOVE中的数据包是zip包,集合了一堆的Lua脚本和资源,而GameKit的数据包是由Blender生成的,也可以包含Lua脚本,正在想呢,这个东西是不是太前卫啊?在Blender中通过一堆的UI去弄逻辑?作为程序员,好像还是比较习惯编写代码。。。。。呵呵,为了Bullet,前段时间刚刚了解了一下Blender的2.4x版本,结果发现GameKit支持的blender的新版(有点想3D Max了)界面差异好大啊。。。也是个打击。。。。。就在此时,无意识的(我也不知道为什么)到Bullet的插件独立网站dynamica
中去逛了一下,才发现,原来Bullet已经有3D Max的插件了,改装自Nvidia开源的PhyX的3D Max插件,(感谢伟大的NVidia公司,虽然它为了自家的Cg对OpenGL的GLSL有些冷遇,导致我需要用AMD的显卡来运行RenderMonkey才方便学习,不过因此我都原谅他了-_-!)甚至还有最新的2011版本的。。。。。天哪,我都在费什么劲啊。。。。晃了那么大一圈,果然,人生在于折腾。。。。。暂时告别下MAYA和Blender了,继续弄弄3D Max先。
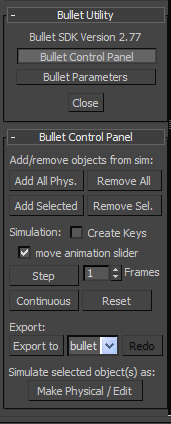
安装完插件后,发现Bullet的3D Max插件文档也比MAYA的要丰富啊(MAYA的主要文档就是指向几个教学视频)。。。。。太感谢开源社区了。。。。。。安装后的3D Max效果如图:
实验
有些奇怪的是,安装完后虽然有Example目录,文档中也提到过Example,但是实际没有任何Example,文档这么详细,使用这么简单,随便学学就能懂了,自己弄个Example^^
先用2D Array复制出一些堆起来的盒子,然后弄个球撞之。。。。。。。。。

呵呵,和文档中的例子截图有些像了^^同时发现复制时是可以带物理属性复制的,但是物理的模拟与3D Max的关键帧动画结合的并不好,不能回滚,导致我想回来截个好图都没有办法-_-!(只能重新再从头模拟一次)
经过试用,发现使用上还是有些不方便,比如每次修改物理属性后都需要add Selected或者add All Phys,这个不太合理,然后就是,目前完全不支持Joint或者Contrainter,也就是说,几乎也就是只有刚体和软体的支持。还有,初始速度和旋转不知道为啥,在我这里也无效,文档中没有提及。
说到这里,无法设定初始速度,那上面的例子是怎么做出来的呢?^^现在揭秘答案:

哈哈...............................
小结
总的来说,bullet的3D Max插件已经比较不错了^^别说别的,就算当一个简单,方便的Bullet文件编辑器用都好啊,比起每个物体通过代码去设置属性,Bullet文件要方便太多了。最重要的是,3D Max对我来说,还是最亲切的。。。。。。暂时聊胜于无了,不够用的时候,再去求助于MAYA插件或者Blender吧。
注意:事实证明,目前的此插件到处的bullet文件无法正常加载,再未更新之前,请直接忽略之。
原创文章作者保留版权 转载请注明原作者 并给出链接
write by 九天雁翎(JTianLing) -- www.jtianling.com
阅读全文....
今天看到电脑玩物
的一则消息:根据XMarks的博客
发布的消息,由于找不到合适的盈利途径,XMarks将于2011年1月10日
停止服务。。。。。看看到这则消息我非常感叹,因为XMarks本身实在是一个非常好用的产品,也算是展示中国互联网环境到底多么开放的一个镜子,(Dropbox也是)一直以来,也根本没有替代品,(Firefox sync可以部分替代,但是XMarks是跨浏览器的)对于一个这么好的产品的死掉,总是引人无限的感叹,不禁引人深思,为什么一个好产品却不能生存下去?
那就是一个产品的关键了 ----盈利,很明显,一个产品只有盈利才能长久的走下去,不能盈利的产品,无论多么优秀,无论用户的评价多么高,无论多么实用,无论满足了多少用户的需求(就像XMarks),最终还是会死掉。这是很悲哀,也很无奈的现实。现代社会发展的最大动力那就是利益,这是资本主义能成为地球上最成功的经济模式的基础,也是人类本性决定的。
我也许会对迅雷,qq,暴风影音无时不刻的广告,突然弹出来影响你工作的广告感到非常的愤怒,也许会受不了搜狗的输入法在升级的时候还隐含带着浏览器的安装的流氓行为,然后连着输入法一起卸载了,并且在卸载原因里面告诉搜狗的人,卸载原因是因为你们做的就是流氓软件,也许会看着flashgot频繁的一次又一次仅仅升级版本号的更新,就是为了让你进去他的主页看看广告而多次想删掉它,但是在XMarks死掉后,也许我能原谅他们了。。。。。比起不想看到广告,我更不想看到它们死掉。。。。。
以前有领导人提出,科学技术是第一生产力,事实上,我想其实他也知道,利益才是第一生产力,所以,他也是这样改革中国经济的。有利益的地方才有生产力。由此能想到app store的繁荣,而android的设备数量(指用户的持有量)虽然已经超过了iOS数量,但是android的程序却远远没有iOS上那么优秀,市场也远远没有那么繁荣,除了android的开发难度会更大(虽然JAVA容易,但是设备太杂),最大的原因其实大家都知道,因为apple培养了很多年的用户付费习惯,这是虽然有不亚于apple fans数量的,但是长期提供免费服务的google所最欠缺的,而,很现实的,能让开发者赚钱的地方,才有最多,最好的开发者。
在中国,有的看起来还算懂经济的人甚至认为版权的保护是不重要的,认为应该自由,我看来非常的悲哀。。。。。无论是软件,电影,音乐,厂商没有利益,你甚至根本享受不到,而版权,咋看起来,那是保护厂商利益与用户作对的,但是事实上,也保护了用户的利益,因为只有他们存在盈利的可能,你才能有更好的软件可用。不要拿几个小小的特例来说事,(比如Unix的发展因为版权问题受到一些阻碍啥的),你能不能够想象一个没有版权保护的世界?
还有观点认为版权啥的那是支撑着厂商暴利的东西,需要强烈反对,其实,这个世界暴利的东西只有权利,市场上实在太少,能够存在的时间也太短了,因为一旦暴利,其他人早就一拥而上了。而IT产品算是个比较特别的例子,我常常看到别人分析apple产品(比如iPhone)的成本,那就是将所有零部件的价格加起来,然后说apple实在暴利,其实我倒是不反对apple的东西比别的厂商利润高,但是这样计算的逻辑也实在太搞笑了,
那么软件行业就更特别了,
难怪有人同理提出windows的生产成本就3块钱,一个3块钱的东西,要中国人花几十块几百块去买,那就是天方夜谭了。其实这里有个小故事,我在gameloft工作时参与制作的spiderman,售价6.99美元,在app store 0.99就能买到很优秀的游戏时,这个售价还是比较高的了,所以我虽然的确第一时间购买,(仅仅因为自己开发过)但是还是和以前同事抱怨了一下,卖的好贵啊。。。。。同事的回答非常直接,看部电影还不几十块,这是消费观念的问题。的确,消费观念哪,在中国享受习惯了免费的软件,潜意识认为软件都可以免费用了,就算卖0.99美元(7块钱在中国其实还可以买什么?)都会觉得贵的。
同理,为啥中国有着还算发达的软件业但是却几乎没有自己真正的好的软件产品/品牌,为啥今天中国的单机游戏,除了回合制RPG还是回合制RPG?(即使是回合制RPG都少了)很多人曾经说,中国的PC能够这么快的普及,盗版是个很重要的因素,因为降低了中国人使用PC的成本,所以上面其实是故意纵容的,但是其实从长久来看,损害的是整个中国的软件产业。从更大范围来看,也降低了很多国外厂商开发中文软件的兴趣,为啥那么多的软件,游戏有7,8国语言,但是却没有中文?因为这个原因,倒是助长了民间汉化的热情。其实总的来说,最后还是损害了用户自身的利益。
有人反对仅仅谈及利益,所以有开源软件,但是同时,有人认为开源软件损害了真正软件开发者的利益,那是洪水猛兽。其实,当经济发展到一定地步,人类不愁吃,不愁穿了,才会有除了生产活动外的其它活动,比如娱乐,比如开源项目。大部分的开源项目,都还是以兴趣为基础的,而兴趣,不是连饭的吃不饱的人能够多想的,这也是中国很难有优秀的开源项目的原因。这也是为啥中国有的开发者(还在吃饭阶段)认为开源软件(发达国家已经脱离吃饭阶段了)损害了自己的利益。无论多少成功的开源项目最后创造了很大的经济效益(比如MySQL),那都仅仅是开源项目的特例而已。
谈到开源,也许xmaks可以效仿blender,商业上失败,走开源的道路,起码最后还能活下来。。。。。
其实写到这里,自己都不知道自己在写些什么了。。。。。仅仅作为看到XMarks死掉后的一次的感叹吧。
阅读全文....


左边的是我做的,右边的是女朋友做的,大家评评看,哪个好看啊^^
***********************************************
哈哈,最后评论的结果似乎我就输了一点点啊。。。。。。。感谢各位捧场^^
阅读全文....
write by 九天雁翎(JTianLing) -- www.jtianling.com
讨论新闻组及文件
当想要在iPhone上使用某个3D引擎的时候,感觉我这水平,自己写好像还不现实,学到自己能写都不知道要到何年何月了,于是折腾过没有官方支持但是比较简单而且我比较熟悉的Irrlicht。虽然的确成功了(见我原来的文章
),
但是弄2D游戏的时候,(用其他引擎)经历过一些痛苦的事情后,我发现强大,成熟的引擎,以及官方的支持是多么重要。。。。。于是,虽然Ogre的效率在
iPhone上还有些难以承受,但是,我还是希望学习学习,并将Ogre作为优先使用的3D引擎。谁叫Ogre那么流行呢?将来要是弄老本行,去做网络游
戏,估计也不错^^
本文写作目的:
1.Ogre的基础模版程序
是Ogre在iPhone平台的模版程序的基础,但是此模版程序没有太多的说明和注释,作者仅仅是说程序具有自解释性。。。。。我这里代为简单解释一下。。。。
2.Ogre虽然是跨平台引擎,但是既然跨平台,在各平台就会有些差异存在,而从桌面程序到iPhone这样的移动平台,差异就更大了,我这里不从源码的角度,仅仅从示例程序对Ogre的使用角度指出这些差异。
而怎么在iPhone上编译运行Ogre,怎么样安装Ogre为iPhone做的项目模版,因为有官方支持嘛,下个SDK
,非常容易,不像Irrlicht那样需要调整很多东西,所以,这些都不是本文的重点,大家自己摸索一下吧。本文也不是Ogre的入门教程,这个请去看Ogre的WIKI
,也有中文版
。(但是WIKI的中级教程有些老,代码一般不能直接在新版本的Ogre和CEGU中工作,但是理解后,稍微进行点改动就行了,中文版可能更老,我没有看,推荐还是去看原版的好,毕竟都是很简单的东西)
基础框架了解
在弄清楚一切之前,利用Ogre的iPhone的基础框架,可以得到以下的运行效果:
一个癞蛤蟆一样的Ogre标识模型。。。。。我见过最难看的一个。。。。。。
先在机器上运行一下,了解这个基础框架实现了哪些功能,主要有下列三个:
1.3D场景中显示了天空盒和一个癞蛤蟆皮Ogre头。。。。
2.2D UI中显示了一系列的Debug信息以及OGRE的标识
3.支持触摸进行Camara的旋转。
然后,下面对此框架的了解除了大致框架外,了解3个功能是在哪里实现的。
基础框架代码分析
主要部分是OgreFramework.h和OgreFramework.cpp两个文件包含的OgreFramework类,这个类虽然内容简单,但是
基本功能齐全,并且,在此简单的框架的基础上,尽量简单的实现了跨平台,这样的话,可以尝试开发Mac,Win32程序,然后移植到iPhone中,以加
快开发速度,缩短开发周期。
如下所示
#if OGRE_PLATFORM == OGRE_PLATFORM_IPHONE
class OgreFramework : public Ogre::Singleton<OgreFramework>, OIS::KeyListener, OIS::MultiTouchListener
#else
class OgreFramework : public Ogre::Singleton<OgreFramework>, OIS::KeyListener, OIS::MouseListener
#endif
OgreFramework是一个C++类,并通过Ogre::Singleton做成单件,并且,这里可以看出来,通过OIS的MultiTouchListener来支持多点触摸。
所有的接口如下:
public:
OgreFramework();
~OgreFramework();
#if OGRE_PLATFORM == OGRE_PLATFORM_IPHONE
bool initOgre(Ogre::String wndTitle, OIS::KeyListener *pKeyListener = 0, OIS::MultiTouchListener *pMouseListener = 0);
#else
bool initOgre(Ogre::String wndTitle, OIS::KeyListener *pKeyListener = 0, OIS::MouseListener *pMouseListener = 0);
#endif
void updateOgre(double timeSinceLastFrame);
void updateStats();
void moveCamera();
void getInput();
bool isOgreToBeShutDown()const{return m_bShutDownOgre;}
bool keyPressed(const OIS::KeyEvent &keyEventRef);
bool keyReleased(const OIS::KeyEvent &keyEventRef);
#if OGRE_PLATFORM == OGRE_PLATFORM_IPHONE
bool touchMoved(const OIS::MultiTouchEvent &evt);
bool touchPressed(const OIS::MultiTouchEvent &evt);
bool touchReleased(const OIS::MultiTouchEvent &evt);
bool touchCancelled(const OIS::MultiTouchEvent &evt);
#else
bool mouseMoved(const OIS::MouseEvent &evt);
bool mousePressed(const OIS::MouseEvent &evt, OIS::MouseButtonID id);
bool mouseReleased(const OIS::MouseEvent &evt, OIS::MouseButtonID id);
#endif
可以从接口看出,此框架设计的使用方式是直接作为变量/成员变量使用,不是希望使用者继承此类。下面分别看各个部分。
初始化
其他部分都属于进一步的操作和更新了,主要部分是Ogre的初始化部分,在initOgre,先看看这个函数:(感觉必要的地方我添加了注释)
/|||||||||||||||||||||||||||||||||||||||||||||||
#if OGRE_PLATFORM == OGRE_PLATFORM_IPHONE
bool OgreFramework::initOgre(Ogre::String wndTitle, OIS::KeyListener *pKeyListener, OIS::MultiTouchListener *pMouseListener)
#else
bool OgreFramework::initOgre(Ogre::String wndTitle, OIS::KeyListener *pKeyListener, OIS::MouseListener *pMouseListener)
#endif
{
// 日志管理的初始化
new Ogre::LogManager();
m_pLog = Ogre::LogManager::getSingleton().createLog("OgreLogfile.log", true, true, false);
m_pLog->setDebugOutputEnabled(true);
// 不是静态链接的时候使用plugins.cfg配置文件,因为iPhone只能使用静态链接方式,没戏了
String pluginsPath;
// only use plugins.cfg if not static
#ifndef OGRE_STATIC_LIB
pluginsPath = m_ResourcePath + "plugins.cfg";
#endif
// Root的创建(Ogre::Root* m_pRoot;)
m_pRoot = new Ogre::Root(pluginsPath, Ogre::macBundlePath() + "/ogre.cfg");
#ifdef OGRE_STATIC_LIB
m_StaticPluginLoader.load();
#endif
// 代码虽然是显示配置对话框的代码,但是示例中不会显示配置对话框,而是直接restore了原来的配置
if(!m_pRoot->showConfigDialog())
return false;
// 渲染窗口的创建及初始化(Ogre::RenderWindow* m_pRenderWnd;)
m_pRenderWnd = m_pRoot->initialise(true, wndTitle);
// iPhone平台特定操作,设定屏幕位置及大小(这些都是随着设备就固定了的),这里的(0,0)还是2维坐标,即屏幕的左上角
// 有意思的是一开始的时候,Ogre就认为iPhone设备是横的。。。。即RenderWnd height: 320 width: 480
// 即状态OR_LANDSCAPELEFT = OR_DEGREE_270
#if OGRE_PLATFORM == OGRE_PLATFORM_IPHONE
m_pRenderWnd->reposition(0, 0);
m_pRenderWnd->resize(m_pRenderWnd->getHeight(), m_pRenderWnd->getWidth());
#endif
// 以下是SceneMgr,Camera,Viewport的创建及初始化,与一般的过程一样
m_pSceneMgr = m_pRoot->createSceneManager(ST_GENERIC, "SceneManager");
m_pSceneMgr->setAmbientLight(Ogre::ColourValue(0.7, 0.7, 0.7));
m_pCamera = m_pSceneMgr->createCamera("Camera");
m_pCamera->setPosition(Vector3(0, 60, 60));
m_pCamera->lookAt(Vector3(0,0,0));
m_pCamera->setNearClipDistance(1);
m_pViewport = m_pRenderWnd->addViewport(m_pCamera);
m_pViewport->setBackgroundColour(ColourValue(0.8, 0.7, 0.6, 1.0));
m_pCamera->setAspectRatio(Real(m_pViewport->getActualWidth()) / Real(m_pViewport->getActualHeight()));
m_pViewport->setCamera(m_pCamera);
// OIS的部分,构造的方式为了跨平台,所以有些独特^^通过字符串的方式来索引参数创建,
// 传递的参数是窗口的句柄,但是也转换成string了
unsigned long hWnd = 0;
OIS::ParamList paramList;
m_pRenderWnd->getCustomAttribute("WINDOW", &hWnd);
paramList.insert(OIS::ParamList::value_type("WINDOW", Ogre::StringConverter::toString(hWnd)));
m_pInputMgr = OIS::InputManager::createInputSystem(paramList);
// OIS有MultiTouch的支持,但是在这个框架中还是直接赋值给m_pMouse(这个变量已经根据宏分别创建了)
#if OGRE_PLATFORM != OGRE_PLATFORM_IPHONE
m_pKeyboard = static_cast<OIS::Keyboard*>(m_pInputMgr->createInputObject(OIS::OISKeyboard, true));
m_pMouse = static_cast<OIS::Mouse*>(m_pInputMgr->createInputObject(OIS::OISMouse, true));
m_pMouse->getMouseState().height = m_pRenderWnd->getHeight();
m_pMouse->getMouseState().width = m_pRenderWnd->getWidth();
#else
m_pMouse = static_cast<OIS::MultiTouch*>(m_pInputMgr->createInputObject(OIS::OISMultiTouch, true));
#endif
// 这里可以参考此类的构造函数,即允许构造此类的时候,传递外来的输入响应对象。
#if OGRE_PLATFORM != OGRE_PLATFORM_IPHONE
if(pKeyListener == 0)
m_pKeyboard->setEventCallback(this);
else
m_pKeyboard->setEventCallback(pKeyListener);
#endif
if(pMouseListener == 0)
m_pMouse->setEventCallback(this);
else
m_pMouse->setEventCallback(pMouseListener);
// 读取配置,与一般的情况一样,只是多了个m_ResourcePath作为基础目录,为Mac和iPhone准备的。
// 这两个平台因为用了Bundle,所以与PC有些不一样
Ogre::String secName, typeName, archName;
Ogre::ConfigFile cf;
cf.load(m_ResourcePath + "resources.cfg");
Ogre::ConfigFile::SectionIterator seci = cf.getSectionIterator();
while (seci.hasMoreElements())
{
secName = seci.peekNextKey();
Ogre::ConfigFile::SettingsMultiMap *settings = seci.getNext();
Ogre::ConfigFile::SettingsMultiMap::iterator i;
for (i = settings->begin(); i != settings->end(); ++i)
{
typeName = i->first;
archName = i->second;
// 还是为Mac和iPhone进行了一些特殊处理,英文注释很详细了
#if OGRE_PLATFORM == OGRE_PLATFORM_APPLE || OGRE_PLATFORM == OGRE_PLATFORM_IPHONE
// OS X does not set the working directory relative to the app,
// In order to make things portable on OS X we need to provide
// the loading with it's own bundle path location
if (!Ogre::StringUtil::startsWith(archName, "/", false)) // only adjust relative dirs
archName = Ogre::String(Ogre::macBundlePath() + "/" + archName);
#endif
Ogre::ResourceGroupManager::getSingleton().addResourceLocation(archName, typeName, secName);
}
}
Ogre::TextureManager::getSingleton().setDefaultNumMipmaps(5);
Ogre::ResourceGroupManager::getSingleton().initialiseAllResourceGroups();
// 创建计时器
m_pTimer = OGRE_NEW Ogre::Timer();
m_pTimer->reset();
// 获取Debug的Overlay层,用于输出一些调试信息
m_pDebugOverlay = OverlayManager::getSingleton().getByName("Core/DebugOverlay");
m_pDebugOverlay->show();
m_pRenderWnd->setActive(true);
return true;
}
这个函数的目的是很单纯的,作为框架性代码,没有像Ogre的基础教程createScene函数一样,添加场景创建的代码,仅仅是初始化了一些相关的对象。而这个函数已经完成了此基础框架希望完成的大部分功能了。
输入
keyPressed,mouseMoved在iPhone中是完全没有什么用了,touch的系列接口虽然与iOS SDK基本一致,但是参数上OIS进行了进一步的分装,估计是为了将来方便移植到其他触摸移动平台(比如Android)。
此参数定义如下:
//! Touch Event type
enum MultiTypeEventTypeID
{
MT_None = 0, MT_Pressed, MT_Released, MT_Moved, MT_Cancelled
};
class _OISExport MultiTouchState
{
public:
MultiTouchState() : width(50), height(50), touchType(MT_None) {};
/** Represents the height/width of your display area.. used if touch clipping
or touch grabbed in case of X11 - defaults to 50.. Make sure to set this
and change when your size changes.. */
mutable int width, height;
//! X Axis component
Axis X;
//! Y Axis Component
Axis Y;
//! Z Axis Component
Axis Z;
int touchType;
inline bool touchIsType( MultiTypeEventTypeID touch ) const
{
return ((touchType & ( 1L << touch )) == 0) ? false : true;
}
//! Clear all the values
void clear()
{
X.clear();
Y.clear();
Z.clear();
touchType = MT_None;
}
};
/** Specialised for multi-touch events */
class _OISExport MultiTouchEvent : public EventArg
{
public:
MultiTouchEvent( Object *obj, const MultiTouchState &ms ) : EventArg(obj), state(ms) {}
virtual ~MultiTouchEvent() {}
//! The state of the touch - including axes
const MultiTouchState &state;
};
基本上还是很容易理解的,就是有些奇怪的添加了Z坐标,难道将来会有立体触摸?-_-!OIS的作者想的还真远啊。。。。。。。
此外,这种参数封装还是有些弱的,iOS的SDK要强大一些,直接内置了多次触摸的查询等的支持,OIS为了通用,看来是不行了。
然后,在touchMoved函数中,实现了camera的旋转。
#if OGRE_PLATFORM == OGRE_PLATFORM_IPHONE
bool OgreFramework::touchMoved(const OIS::MultiTouchEvent &evt)
{
OIS::MultiTouchState state = evt.state;
int origTransX = 0, origTransY = 0;
switch(m_pCamera->getViewport()->getOrientationMode())
{
case Ogre::OR_LANDSCAPELEFT:
origTransX = state.X.rel;
origTransY = state.Y.rel;
state.X.rel = -origTransY;
state.Y.rel = origTransX;
break;
case Ogre::OR_LANDSCAPERIGHT:
origTransX = state.X.rel;
origTransY = state.Y.rel;
state.X.rel = origTransY;
state.Y.rel = origTransX;
break;
// Portrait doesn't need any change
case Ogre::OR_PORTRAIT:
default:
break;
}
m_pCamera->yaw(Degree(state.X.rel * -0.1));
m_pCamera->pitch(Degree(state.Y.rel * -0.1));
return true;
}
大部分代码是为了不同的设备方向而进行的参数调整,其实主要也就是Camera的yaw,pitch旋转而已,有意思的是,touch参数里面的相对值的存在,使得旋转速度的设定非常简洁。
调试信息输出
框架类中剩下的还有点用的东西就是调试信息的输出了,代码如下:
//|||||||||||||||||||||||||||||||||||||||||||||||
void OgreFramework::updateStats()
{
static String currFps = "Current FPS: ";
static String avgFps = "Average FPS: ";
static String bestFps = "Best FPS: ";
static String worstFps = "Worst FPS: ";
static String tris = "Triangle Count: ";
static String batches = "Batch Count: ";
OverlayElement* guiAvg = OverlayManager::getSingleton().getOverlayElement("Core/AverageFps");
OverlayElement* guiCurr = OverlayManager::getSingleton().getOverlayElement("Core/CurrFps");
OverlayElement* guiBest = OverlayManager::getSingleton().getOverlayElement("Core/BestFps");
OverlayElement* guiWorst = OverlayManager::getSingleton().getOverlayElement("Core/WorstFps");
const RenderTarget::FrameStats& stats = m_pRenderWnd->getStatistics();
guiAvg->setCaption(avgFps + StringConverter::toString(stats.avgFPS));
guiCurr->setCaption(currFps + StringConverter::toString(stats.lastFPS));
guiBest->setCaption(bestFps + StringConverter::toString(stats.bestFPS)
+" "+StringConverter::toString(stats.bestFrameTime)+" ms");
guiWorst->setCaption(worstFps + StringConverter::toString(stats.worstFPS)
+" "+StringConverter::toString(stats.worstFrameTime)+" ms");
OverlayElement* guiTris = OverlayManager::getSingleton().getOverlayElement("Core/NumTris");
guiTris->setCaption(tris + StringConverter::toString(stats.triangleCount));
OverlayElement* guiBatches = OverlayManager::getSingleton().getOverlayElement("Core/NumBatches");
guiBatches->setCaption(batches + StringConverter::toString(stats.batchCount));
OverlayElement* guiDbg = OverlayManager::getSingleton().getOverlayElement("Core/DebugText");
guiDbg->setCaption("");
}
都是获取到响应的UI元素,然后进行输出,没有太多好讲的。
框架驱动代码
上述的框架还不足以构成一个完成的程序,仅仅是跨平台实现中干了一些脏活,可以跨平台的部分,我们还需要实际的驱动代码来使用这个框架。
这些代码又分两个部分,DemoApp类和AppDelegate类。
DemoApp:
class DemoApp : public OIS::KeyListener
{
public:
DemoApp();
~DemoApp();
void startDemo();
void setupDemoScene();
void setShutdown(bool flag) { m_bShutdown = flag; }
bool keyPressed(const OIS::KeyEvent &keyEventRef);
bool keyReleased(const OIS::KeyEvent &keyEventRef);
private:
void runDemo();
Ogre::SceneNode* m_pCubeNode;
Ogre::Entity* m_pCubeEntity;
bool m_bShutdown;
};
很简洁也很直接的定义,没有去继承使用Ogre的ExampleApplication等类。仅仅继承了KeyListener
,响应keyPressed
和keyReleased
,而在iPhone中我们又不用管。
那么,需要看到就是真实创建天空盒和那个癞蛤蟆头的部分了。
void DemoApp::startDemo()
{
new OgreFramework();
if(!OgreFramework::getSingletonPtr()->initOgre("DemoApp v1.0", this, 0))
return;
m_bShutdown = false;
OgreFramework::getSingletonPtr()->m_pLog->logMessage("Demo initialized!");
setupDemoScene();
runDemo();
}
此函数完成了前面讲到的OgreFramework的创建及初始化,于是,此时,我们Ogre程序需要的root,scene manager, viewport,camera,等东西都已经有了。
下面直接调用setupDemoScene来创建了场景,然后通过runDemo来运行程序(即进入主循环)。
void DemoApp::setupDemoScene()
{
OgreFramework::getSingletonPtr()->m_pSceneMgr->setSkyBox(true, "Examples/SpaceSkyBox");
OgreFramework::getSingletonPtr()->m_pSceneMgr->createLight("Light")->setPosition(75,75,75);
m_pCubeEntity = OgreFramework::getSingletonPtr()->m_pSceneMgr->createEntity("Cube", "ogrehead.mesh");
m_pCubeNode = OgreFramework::getSingletonPtr()->m_pSceneMgr->getRootSceneNode()->createChildSceneNode("CubeNode");
m_pCubeNode->attachObject(m_pCubeEntity);
}
因为初始化完了,那么创建场景的部分就简单了,如上所示,也就几句代码。属于Ogre常规操作,也就不多说了。
//|||||||||||||||||||||||||||||||||||||||||||||||
void DemoApp::runDemo()
{
OgreFramework::getSingletonPtr()->m_pLog->logMessage("Start main loop...");
double timeSinceLastFrame = 0;
double startTime = 0;
OgreFramework::getSingletonPtr()->m_pRenderWnd->resetStatistics();
while(!m_bShutdown && !OgreFramework::getSingletonPtr()->isOgreToBeShutDown())
{
if(OgreFramework::getSingletonPtr()->m_pRenderWnd->isClosed())m_bShutdown = true;
#if OGRE_PLATFORM != OGRE_PLATFORM_IPHONE
Ogre::WindowEventUtilities::messagePump();
#endif
if(OgreFramework::getSingletonPtr()->m_pRenderWnd->isActive())
{
startTime = OgreFramework::getSingletonPtr()->m_pTimer->getMillisecondsCPU();
#if OGRE_PLATFORM != OGRE_PLATFORM_IPHONE
OgreFramework::getSingletonPtr()->m_pKeyboard->capture();
#endif
OgreFramework::getSingletonPtr()->m_pMouse->capture();
OgreFramework::getSingletonPtr()->updateOgre(timeSinceLastFrame);
OgreFramework::getSingletonPtr()->m_pRoot->renderOneFrame();
timeSinceLastFrame = OgreFramework::getSingletonPtr()->m_pTimer->getMillisecondsCPU() - startTime;
}
else
{
#if OGRE_PLATFORM == OGRE_PLATFORM_WIN32
Sleep(1000);
#elif OGRE_PLATFORM == OGRE_PLATFORM_APPLE
sleep(1000);
#endif
}
}
OgreFramework::getSingletonPtr()->m_pLog->logMessage("Main loop quit");
OgreFramework::getSingletonPtr()->m_pLog->logMessage("Shutdown OGRE...");
}
看完这里,代码上是没有什么疑问了,主循环嘛。。。。。。。。不过,对于代码实现的问题上,还是有些问题的,从前面的代码来看,主循环通过
while(!m_bShutdown && !OgreFramework::getSingletonPtr()->isOgreToBeShutDown())
控制,而且里面完全没有帧率控制代码。。。。也没有使用Ogre在教程中提倡的使用FrameListeners的frameRenderingQueued
回调函数来完成update,这个感觉比较奇怪。
而假如是通过
if(OgreFramework::getSingletonPtr()->m_pRenderWnd->isActive())
即,是否Actice来控制帧率也不正常,这个应该是窗口在后台不需要处理输入的时候使用的,而且一次sleep了1秒钟,也不可能胜任这个工作。
带着疑问调试此函数的代码,发现根本没有调用此函数。。。。。。-_-!
这里搞这么多#if OGRE_PLATFORM != OGRE_PLATFORM_IPHONE,结果iPhone中根本不调用,还是比较具有迷惑性的。。。。。。
真实的版本,当然就看AppDelegate了,AppDelegate是ObjC类。。。。。。看到这里,突然感觉,我虽然仅仅是最近用了几个月的ObjC,但是因为最近一直在用Objc,竟然感觉比用了好几年的C++更加亲切了。。。。。-_-!
AppDelegate
在main函数中,首先看到AppDelegate的使用:
int main(int argc, char **argv)
#endif
{
#if OGRE_PLATFORM == OGRE_PLATFORM_IPHONE
NSAutoreleasePool * pool = [[NSAutoreleasePool alloc] init];
int retVal = UIApplicationMain(argc, argv, @"UIApplication", @"AppDelegate");
[pool release];
return retVal;
#else
}
所
以,我原本以为AppDelegate就是一个从ObjC到DemoApp的一个小外壳而已,处理一些简单的delegate回调,结果发现根本不是这
样,在iPhone版本的示例程序中,AppDelegate才是实际的DemoApp,而原来DemoApp,其实AppDelegate只是使用了其
setup场景的部分而已。原来我也是只猜到了开始,但是猜不到这个结果。。。。。。。
在applicationDidFinishLaunching中经过了一些在iPhone中必须进行的一些window,view操作后,直接进入了主题,go函数,看看go函数:
- (void)go {
NSAutoreleasePool * pool = [[NSAutoreleasePool alloc] init];
try {
new OgreFramework();
if(!OgreFramework::getSingletonPtr()->initOgre("DemoApp v1.0", &demo, 0))
return;
demo.setShutdown(false);
OgreFramework::getSingletonPtr()->m_pLog->logMessage("Demo initialized!");
demo.setupDemoScene();
OgreFramework::getSingletonPtr()->m_pRenderWnd->resetStatistics();
if (mDisplayLinkSupported)
{
// CADisplayLink is API new to iPhone SDK 3.1. Compiling against
earlier versions will result in a warning, but can be dismissed
// if the system version runtime check for CADisplayLink exists in
-initWithCoder:. The runtime check ensures this code will
// not be called in system versions earlier than 3.1.
mDate = [[NSDate alloc] init];
mLastFrameTime = -[mDate timeIntervalSinceNow];
mDisplayLink = [NSClassFromString(@"CADisplayLink") displayLinkWithTarget:self selector:@selector(renderOneFrame:)];
[mDisplayLink addToRunLoop:[NSRunLoop currentRunLoop] forMode:NSDefaultRunLoopMode];
}
else
{
mTimer = [NSTimer scheduledTimerWithTimeInterval:(NSTimeInterval)(1.0f / 60.0f) * mLastFrameTime
target:self
selector:@selector(renderOneFrame:)
userInfo:nil
repeats:YES];
}
} catch( Ogre::Exception& e ) {
std::cerr << "An exception has occurred: " <<
e.getFullDescription().c_str() << std::endl;
}
[pool release];
}
原来这才是真正驱动OgreFramework的地方啊。。。。。。前面那都是迷惑人的。。。。
new OgreFramework();
if(!OgreFramework::getSingletonPtr()->initOgre("DemoApp v1.0", &demo, 0))
return;
demo.setShutdown(false);
OgreFramework::getSingletonPtr()->m_pLog->logMessage("Demo initialized!");
demo.setupDemoScene();
在iPhone版本中,在go函数中进行了OgreFramework的创建及初始化,然后调用demo的setupDemoScene进行场景的创建(前面分析的也就这一部分是对的了。。。。。。其他demo部分分析仅适用于其它版本)。
if (mDisplayLinkSupported)
{
// CADisplayLink is API new to iPhone SDK 3.1. Compiling against
earlier versions will result in a warning, but can be dismissed
// if the system version runtime check for CADisplayLink exists in
-initWithCoder:. The runtime check ensures this code will
// not be called in system versions earlier than 3.1.
mDate = [[NSDate alloc] init];
mLastFrameTime = -[mDate timeIntervalSinceNow];
mDisplayLink = [NSClassFromString(@"CADisplayLink") displayLinkWithTarget:self selector:@selector(renderOneFrame:)];
[mDisplayLink setFrameInterval:mLastFrameTime];
[mDisplayLink addToRunLoop:[NSRunLoop currentRunLoop] forMode:NSDefaultRunLoopMode];
}
可以看到此处是通过iPhone的CADisplayLink类来完成刷新及帧率控制的,(前面还特意检查了版本,以判断当前iPhone版本是否支持此特性,3.1以后才有的东西)而renderOneFrame里面的内容很简单,这里就不讲了。
看看CADisplayLink吧,在apple的文档中,有如下描述:
A
CADisplayLink object is a timer object that allows your application to
synchronize its drawing to the refresh rate of the display.
很明显,这个iPhone平台特定的东西估计要比Ogre跨平台的FrameListener要好用一些,所以此基础框架程序中使用了这个iPhone原生的东西。
不过这个代码有个问题:
mDate = [[NSDate alloc] init];
mLastFrameTime = -[mDate timeIntervalSinceNow];
[mDisplayLink setFrameInterval:mLastFrameTime];
此时mLastFrameTime一般是个远小于1的变量,而在apple的文档中有如下描述:
frameInterval
The number of frames that must pass before the display link notifies the target again.
@property(nonatomic) NSInteger frameInterval
Discussion
The
default value is 1, which results in your application being notified at
the refresh rate of the display. If the value is set to a value larger
than 1, the display link notifies your application at a fraction of the
native refresh rate. For example, setting the interval to 2 causes the
display link to fire every other frame, providing half the frame rate.
Setting this value to less than 1 results in undefined behavior and is a programmer error.
注
意最后一句。。。。。。设置成小于1的值会导致未定义行为,并且是一个错误。。。。。既然默认是1,那么其实后面的frameInterval根本不用设
置。(原程序能够正常的运行,估计apple还是进行了一定的错误处理,当小于1时还是设置成1了)为了安全起见,这一句还是删掉吧。事实上,删掉后,运
行还是正常,此时使用默认值1,也就是每次显示刷新调用一次此函数。
相对的,看Cocos2D for iPhone的代码,现在默认的director类CCDisplayLinkDirector,对DisplayLink的使用实现代码如下:
int frameInterval = (int) floor(animationInterval_ * 60.0f);
CCLOG(@"cocos2d: Frame interval: %d", frameInterval);
displayLink = [NSClassFromString(@"CADisplayLink") displayLinkWithTarget:self selector:@selector(preMainLoop:)];
[displayLink setFrameInterval:frameInterval];
[displayLink addToRunLoop:[NSRunLoop currentRunLoop] forMode:NSDefaultRunLoopMode];
注
意,这里的animationInterval是秒为单位的表示时间间隔的变量,但是这里没有直接使用此变量来设定frameInterval,而是乘以
了60,(Cocos认为iPhone设备的刷新率近似为60)应该来说,这才是正确用法。。。。。。。我看来可以向Ogre的开发组提交个bug
了。。。。。。
原创文章作者保留版权 转载请注明原作者 并给出链接
write by 九天雁翎(JTianLing) -- www.jtianling.com
阅读全文....
write by 九天雁翎(JTianLing) -- www.jtianling.com
讨论新闻组及文件
现在在国内做游戏,似乎怎么都绕不开OGRE和CEGUI的学习,因为他们实在是太流行了。。。。。OGRE在Google中搜索game engine长期排在第一,而CEGUI又几乎是OGRE的官方UI。。。毕竟不是盖的。我第一份工作的时候就做过一些CEGUI相关的工作,(但是那时候引擎不是OGRE)但是一直没有太深入的学习,然后在游戏开发的路上绕了很大一圈,接触了OpenGL(ES),以及各色2D,3D引擎,最后似乎还是回到了OGRE和CEGUI,所以还是有些感慨。。。。。。
当自己需要从头开始做某些基础工作的时候,与拿着成熟的框架和工程感觉还是有些不一样的。比如CEGUI和OGRE的配置。。。。。。。
主要参考资料来自于《Building CEGUI for Ogre / OgreRenderer
》。
现在(2010.9.13)CEGUI的最新版是0.72,到这里下载
。(源码版本)
然后,将CEGUI解压到某个地方。我这里选择的是OGRE的目录下。
此时,CEGUI-0.7.2/projects/premake中可以看到批处理build_vs2008.bat,运行一下就可以得到想要的VS2008工程,第一次我尝试的时候编译此工程,然后拷贝相关的lib,dll到OGRE的相关目录,会发现还是少一个文件,debug版本是CEGUIOgreRenderer_d.lib,然后我发现还需要配置。这里感觉就没有那么直观了。。。。。。。。。不属于work out of box,这也是本文写作的唯一有效目的。。。。。
配置:
1。在批处理的目录下的config.lua文件中,修改如下两行内容:
OGRE_PATHS = { "..", "include/OGRE", "lib" }
OIS_PATHS = { "..", "include/OIS", "lib" }
这里第一个字符串的路径根据你将CEGUI解压的地方来配置,我这里由于CEGUI已经解压到OGRE的目录下,所以仅仅使用父目录就可以了。
2。在config.lua中,将OGRE_RENDERER那一行设为true,如下:
OGRE_RENDERER = true
3。在新版的OGRE中增加了对boost的依赖,所以还需要配置一下boost。(修改CEGUI_EXTRA_PATHS的内容)
我这里是:
CEGUI_EXTRA_PATHS = {
{ "../boost_1_42", "", "lib", "CEGUIOgreRenderer" },
}
此时会发现CEGUI的solution中会多出一个CEGUIOgreRenderer的工程。并且,经过前面的配置,路径都已经配置好了。
这里有些惊喜的是,发现了irrlicht相关的东西,呵呵,将来也可以尝试,个人对irrlicht的简单易用也印象深刻,不知道在学了OGRE后,下次还有没有机会再次使用。
然后,编译就好了,会报一堆的警告。。。。。。。。。。。。。感觉这些代码写的都有问题。。。。。在公司的代码里面,经常是一句warning都不能有的,而且这些waring都是类型转换警告。。。。估计在某些时候肯定会有问题。。。暂时不管了。
事实上,最后还会有个错误,
LINK : fatal error LNK1104: cannot open file 'OgreMain_d.lib'
因为配置的时候好像不能分debug/release来配置,(前面的文档没有讲这一点,我也没有深究了。。。。也许有办法吧)而OGRE的lib目录事实上又分debug/release子目录的。。。。。所以,其实看起来蛮自动化的配置,最后还是少不了手动干预一下。
手动修改lib目录后,问题解决。
此时将编译出来的lib,dll都拷贝到OGRE的相关目录,(因为我不准备修改CEGUI,所以简单的就拷贝了,需要修改CEGUI的,可以直接修改CEGUI工程配置,设置为编译后拷贝到相应目录)就可以直接在OGRE中使用CEGUI了,只需要再配置工程的CEGUI include目录就好。
然后,当遇到过这么多坑以后,满以为总该顺利了。。。。。。事实上,还有一个大坑在前面等着你,在最新的CEGUI版本中,你会遇到“应用程序正常初始化(0xc0150002)失败”错误,而且不会给你任何头绪。。。。。其实我费了这么多劲,非要从源码编译CEGUI和OGRE,而不是使用各自的SDK,就是因为使用SDK的时候碰到这个问题了,从经验判断应该是库的编译版本不匹配的问题,结果我自己将所有的源码都编译了一次了,还是有问题。。。。。。。。。无奈之余,在网上搜索了一下,碰到这个问题的人还不是少数。
这个哥们描述的背后的故事
。。。。。还提供了hack解决方案,牛,可惜我是用VS2008的,VS2005那个补丁不适合我,运行安装不了,我也还是希望通过正常的补丁途径解决。而这个哥们提供了完善的解决方案
。基本上,简单的说,VS2008的解决方案就是下载正确的依赖文件VC90
那个,或者直接下CEGUI SDK VS2008的SDK
,只是千万不要下VC80任何相关的东西。。。。(我很郁闷MS竟然不让VS2008在这种程度上支持VS2005,起码也能够让任何VS2005编译的东西在VS2008得到直接的支持啊)然后为自己的VS2008打上SP1补丁,就好了。这个问题真的折腾了我挺久,希望大家不要再继续被折腾了。。。。。。。。。。。。。
原创文章作者保留版权 转载请注明原作者 并给出链接
write by 九天雁翎(JTianLing) -- www.jtianling.com
阅读全文....
今天看到Irrlicht作者Ambiera推的一则有意思的消息,虽然其实与iPhone开发关系不大,但是因为牵涉到Windows Phone 7和HTML5,我还是大概看完了。
消息原地址来自于:http://bit.ly/d3wEqD
大概的含义是某人刚到MS总部一周,发现了MS内部在HTML5和SilverLight技术上的派系之争。并且,提到WPF已经死掉。
"Right now there’s a faction war inside Microsoft over HTML5 vs
Silverlight. oh and WPF is dead.. i mean..it kind of was..but now..
funeral."
文中还提到,HTML5是WPF的替代者,并且MS还是会对HTML执行它惯用的"拥抱并且扩展"(Embrace and extend")战略,然后分支HTML5,用本地化的Windows API来特殊化Windows下的JS/HTML5。
“HTML5 is the replacement for WPF.. IE team want to fork the HTML5 spec by bolting on custom windows APi’s via JS/HTML5”
从这个观点来看,SilverLight会边缘化,但是同时也看到了新的信息,因为新的Windows Phone 7中,普通app的开发平台都是SilverLight了,可见MS并不希望SilverLight边缘化。
这个其实并不是我最感兴趣的,最有意思的是,Hadi Hariri在他的博客上发表了一篇反SilverLight的文章。“
见:http://tinyurl.com/3x7r8p8
文中提到了很多有趣的观点,文后的评论质量更加是非常高,很多评论的信息量已经足够独立成文了,想到国内的"顶顶族"和“家具党”,我真是感到了国际差距。。。。。
文章和评论可以看出,国外对MS那种老是完全放弃老技术对开发者的伤害还是很大的,虽然从技术革新来上看,这是技术上很大胆和进步。另外,国外也的确有人很注意跨平台(CP),谈及MS的时候,Linux和MacOS都有提及,甚至有人说在做网页开发的时候,公司里面几乎没有后人真的装Windows来开发,仅仅通过虚拟机装Windows XP用于测试IE。感觉国外也有人不希望与MS"绑定"在一起.
最激进的MS反对者提出,Windows Phone 7最终没有会用,就是因为开发者都不想光是为了Windows Phone 7的开发而迁移到SilverLight平台,所以会鲜有开发者支持,MS有这个功夫,不如多花点时间
把自己的其他东西弄好
。
当然,也有人支持MS的,
具体内容大家自己去看吧,其实最感叹的是国外这些哥们谈论完全不同技术问题,并且带有派系之针的时候纯粹是就技术论技术,并且一条一条论据摆出来分析,结合周围实际情况来讲,我最疑问的是,为啥这样讨论都没有带骂娘的人生攻击呢?。。。。。。。。
背景参考:在IE9中,MS会支持新的HTML5技术,这是与其SilverLight直接竞争的技术,同时,MS新推的Windows Phone 7中,普通app的开发平台是Silverlight。。。。。。
阅读全文....
又娱乐了一回。。。。惭愧惭愧。。。。不过实在是很有意思,想转一下。来自:http://www.zxxblog.com/606

阅读全文....
write by 九天雁翎(JTianLing) -- www.jtianling.com
讨论新闻组及文件
本文应该是该系列的最后一篇,看看一个物体在Orx中从载入到显示的完整流程。
在Orx,渲染部分,一直与object纠缠在一起,一般不直接由外部使用。最主要的函数是2个:
orxDisplay_LoadBitmap
orxDisplay_BlitBitmap
假如还需要加一个,那就是
orxDisplay_ClearBitmap
事实是向作者讨教过显示一个位图最快的方式,大概是下面这个样子的:
void
GameApp::Update(const
orxCLOCK_INFO *_pstClockInfo, void
*_pstContext) {
//m_states.top()->Update(_pstClockInfo->fDT);
orxDisplay_ClearBitmap(orxDisplay_GetScreenBitmap(), orx2RGBA(0
, 0
, 0
, 0
));
orxDisplay_BlitBitmap(orxDisplay_GetScreenBitmap(), spstBitmap, 100.0f
, 000.0f
, orxDISPLAY_BLEND_MODE_ALPHA);
}
orxSTATUS GameApp::Init() {
spstBitmap = orxDisplay_LoadBitmap("Dragon.png"
);
//orxDisplay_SetDestinationBitmap(orxDisplay_GetScreenBitmap());
orxCLOCK *pstClock = orxClock_Create(orx2F(0.05f
), orxCLOCK_TYPE_USER);
/*
Registers our update callback
*/
orxClock_Register(pstClock, sUpdate, orxNULL, orxMODULE_ID_MAIN, orxCLOCK_PRIORITY_NORMAL);
return
orxSTATUS_SUCCESS;
}
也就是说,事实上也可以在Orx不通过配置,直接通过API,调用上面的3个函数完成图形的绘制。
orxDisplay_LoadBitmap
图形信息载入后保存的结构是:
/*
* Internal bitmap structure
*/
struct
__orxBITMAP_t
{
GLuint uiTexture;
orxBOOL bSmoothing;
orxFLOAT fWidth, fHeight;
orxU32 u32RealWidth, u32RealHeight, u32Depth;
orxFLOAT fRecRealWidth, fRecRealHeight;
orxCOLOR stColor;
orxAABOX stClip;
};
在图形的载入过程中,在Orx中使用了SOIL这个外部的库,用于支持多种图形格式,而又可以不直接与jpeg和png的那一堆解压库打交道,说实话,就我使用那些库的感觉来说,为了通用及功能强大,API还是太复杂了一些,而且文档并不详细,而是用SOIL,Orx仅仅用
/* Loads image */
pu8ImageData = SOIL_load_image(_zFilename, (int *)&uiWidth, (int *)&uiHeight, (int *)&uiBytesPerPixel, SOIL_LOAD_RGBA);
这么一句,就支持了多种图形文件。
在orxDisplay_LoadBitmap的函数调用中,对图形的宽和高还是进行了修正,代码如下:
/* Gets its real size */
uiRealWidth = orxMath_GetNextPowerOfTwo(uiWidth);
uiRealHeight = orxMath_GetNextPowerOfTwo(uiHeight);
使得宽高都位置在2的幂上,以支持更多的显卡。
然后保存好图形的相关信息,手工调用OpenGL进行纹理绑定:
/*
Creates new texture
*/
glGenTextures(1
, &pstResult->uiTexture);
glASSERT();
glBindTexture(GL_TEXTURE_2D, pstResult->uiTexture);
glASSERT();
glTexImage2D(GL_TEXTURE_2D, 0
, GL_RGBA, pstResult->u32RealWidth, pstResult->u32RealHeight, 0
, GL_RGBA, GL_UNSIGNED_BYTE, pu8ImageBuffer);
glASSERT();
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_CLAMP_TO_EDGE);
glASSERT();
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_CLAMP_TO_EDGE);
glASSERT();
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, (pstResult->bSmoothing != orxFALSE) ? GL_LINEAR : GL_NEAREST);
glASSERT();
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, (pstResult->bSmoothing != orxFALSE) ? GL_LINEAR : GL_NEAREST);
glASSERT();
用下面的语句删除临时载入的资源:
/* Deletes surface */
SOIL_free_image_data(pu8ImageData);
最后图形的相关信息,包括通过OpenGL载入的纹理的句柄,都保存__orxBITMAP_t
结构中。
orxDisplay_ClearBitmap
主要就是如下几句:
/*
Clears the color buffer with given color
*/
glClearColor((1.0f
/ 255.f
) * orxU2F(orxRGBA_R(_stColor)), (1.0f
/ 255.f
) * orxU2F(orxRGBA_G(_stColor)), (1.0f
/ 255.f
) * orxU2F(orxRGBA_B(_stColor)), (1.0f
/ 255.f
) * orxU2F(orxRGBA_A(_stColor)));
glASSERT();
glClear(GL_COLOR_BUFFER_BIT);
只要了解OpenGL,这个没有什么好说的。
orxDisplay_BlitBitmap
此函数是渲染流程中最主要的函数,其中又调用了如下函数完成绘制:
orxDisplay_GLFW_DrawBitmap(_pstSrc, _eSmoothing, _eBlendMode);
orxDisplay_GLFW_DrawBitmap
orxDisplay_GLFW_DrawBitmap分两部分:
1。用orxDisplay_GLFW_PrepareBitmap指定当前的纹理,及通过当前渲染的配置,调整OpenGL渲染状态,比如是否抗锯齿,是否应用定点色等。
2。实际进行纹理的映射,然后最终调用
/* Draws arrays */
glDrawArrays(GL_TRIANGLE_STRIP, 0, 4);
完成图形的绘制。
全系列小结
到这里,全部的Orx源代码阅读就结束了。Orx算是一个相对较小,实现游戏相关概念不多,但是相对完整,并且有特色的的一个游戏引擎了。完整的看下来,会发现,在2D游戏引擎中,其实渲染的这一部分代码非常少,基本上也就是一个OpenGL使用纹理映射显示位图的翻版,(可参考这里
)主要的部分在于整个游戏引擎的组织。这一点上,作为完全使用C语言完成的Orx来说,代码的组织上还是非常有可借鉴之处的。每个单独的模块都是用几个关键的结构,构成一个局部的(单文件中)全局结构实现,然后仅对外开放必要的接口,基本上能做到仅仅看到结构,就能了解整个模块的大概实现,看起来非常的清晰。在部分模块的实现中,也借鉴的面向对象的实现方式,实现了可配置的简单的update及init,setup等操作。这些都是引擎中的亮点。
假如说Orx有什么缺点的话,通过通读代码,我最大的感觉就是因为其实现的大量可配置的特点,给引擎带来的太多额外的负担,比如update,init,setup等模块的实现,几乎都是从这个目的出发的,是引擎变得复杂了很多,而且,因为这个关系,引擎内部之间的模块设计,从物理设计上来看,太多的交错,离正交太远。
这些可能是从一开始作者对Orx的数据驱动的理念是相关的,在作者看来,外部使用者甚至就不应该直接使用其更多的API,而是直接仅仅使用配置。而从我个人的感觉,已经在推广Orx的过程中一些中国使用者的反馈来看,在没有合适编辑的情况下,config的配置负担在Orx比编写和修改代码的负担要重更多,而且总体结合起来的易用性及开发的速度上面并不比一个不需要配置驱动但是API设计合理的传统2D引擎要强。而且,在使用上并没有获得更好的易用性,在实现上由于一开始的理念存在,也使得实现更加复杂。个人感觉有点得不偿失。Orx的设计是超前,但是目前来看,传统之所以成为传统,还有有其道理所在。
个人认为,Orx可改进的方向有几个:
其一,Orx的底层就是应该通过传统的手法去构建,不要弄的配置那么深入,各个模块需要那么灵活的配置,实现上的负担可以减轻很多。并且,这一部分的API设计也是可以对外的。也有文档指明各个API的搭配使用,外部使用者可以在完全不使用配置的情况下,将Orx作为一个普通的不是数据驱动的引擎来使用。虽然这个比较不符合作者的初衷。
其二,配置驱动的设计完全构建在上面那一层传统的不是数据驱动的那一层游戏引擎上,只要下层的API设计合理,这完全可以做到。对于普通使用者来说,学习曲线也可以更加平缓,在学习和了解了底层的API使用后,配置仅仅是用于加速自己设计的实现,而不是仅仅知道配置,一旦某个地方的配置出现隐晦的错误就一筹莫展(这个问题我自己和很多中国用户都出现过),因为了解底层的API 的使用,出现类似问题,通过在上层的调试,(即读取配置使用底层接口这一层)就能很容易的发现。而且,配置的使用不应该成为强制性的,这仅仅是使用者提高开发速度的一种方式,假如使用者认为底层的API已经足够使用,完全可以不用配置层。前面这两条说简单点就是将数据驱动与传统的接口相分离,而不是真的作为引擎的强制项。
其三,配置其实不能完全等同与一般意义的数据,需要手工编写的格式严格的配置,会给使用者带来很大的负担,我有时甚至觉得写代码比写配置更加容易,起码出错了更加方便调试。这些问题就需要能够保证生成正确配置的工具来解决了。作为了游戏引擎,Orx在这方面还比较欠缺,因为作者“憎恨”写UI的特点,估计这也不能靠作者来完成了,需要Orx的社区力量来完成。没有工具生成配置的配置驱动,根本就称不上真正的数据驱动,不过是将写代码的负担移到写配置而已。。。。。。。。。。。。。。。。。。
以上纯属个人看法,而历史证明,由于懂得东西不是很多,所以我的个人看法很多是不正确的,比如前面我提到的Orx的list实现很奇怪的问题
。。。。。。。。。。。。。。。。。。所以请读者不要轻信上述问题,那仅仅是一家之言。
原创文章作者保留版权 转载请注明原作者 并给出链接
write by 九天雁翎(JTianLing) -- www.jtianling.com
阅读全文....
write by 九天雁翎(JTianLing) -- www.jtianling.com
讨论新闻组及文件
这一节,看的是我感觉Orx实现的最为"有技术"的部分了,C语言实现面向的技术,在SDL的源码
中看到过一种方法,Orx实现的是另外一种,相对来说可以支撑更加复杂和灵活的结构。
在SDL中,用一个结构中的函数指针的替换来实现了面向对象的效果。在Orx中则是一种类似大量需要最基础基类的面向对象语言一样,提供了所有对象的基类(结构)orxSTRUCTURE,其他结构需要"继承"(其实在Orx是包含orxSTRUCTURE)自这个结构,然后在使用时,可以在获取orxSTRUCTURE指针的情况下获得真正的"子类"对象指针,并且使用。虽然说是一种模拟面向对象的技术,其实也有些像handle的技术。
在Orx中大量的结构都是在这个框架之下的。
下面是Structure的ID列表,下面这些都是属于Orx“面向对象体系”的一部分。
/*
* Structure IDs
*/
typedef
enum
__orxSTRUCTURE_ID_t
{
/*
*** Following structures can be linked to objects ***
*/
orxSTRUCTURE_ID_ANIMPOINTER = 0
,
orxSTRUCTURE_ID_BODY,
orxSTRUCTURE_ID_CLOCK,
orxSTRUCTURE_ID_FRAME,
orxSTRUCTURE_ID_FXPOINTER,
orxSTRUCTURE_ID_GRAPHIC,
orxSTRUCTURE_ID_SHADERPOINTER,
orxSTRUCTURE_ID_SOUNDPOINTER,
orxSTRUCTURE_ID_SPAWNER,
orxSTRUCTURE_ID_LINKABLE_NUMBER,
/*
*** Below this point, structures can not be linked to objects ***
*/
orxSTRUCTURE_ID_ANIM = orxSTRUCTURE_ID_LINKABLE_NUMBER,
orxSTRUCTURE_ID_ANIMSET,
orxSTRUCTURE_ID_CAMERA,
orxSTRUCTURE_ID_FONT,
orxSTRUCTURE_ID_FX,
orxSTRUCTURE_ID_OBJECT,
orxSTRUCTURE_ID_SHADER,
orxSTRUCTURE_ID_SOUND,
orxSTRUCTURE_ID_TEXT,
orxSTRUCTURE_ID_TEXTURE,
orxSTRUCTURE_ID_VIEWPORT,
orxSTRUCTURE_ID_NUMBER,
orxSTRUCTURE_ID_NONE = orxENUM_NONE
} orxSTRUCTURE_ID;
这里的对象与前面讲到的
过的module其实是有些重叠的。但是总体上,module更加偏向于实现的概念,这里的对象更加倾向于游戏中实际对应的对象,也就是更加高层一些。
共有结构:
orxSTRUCTURE这个最基础基类的结构非常简单:
/*
* Public structure (Must be first derived structure member!)
*/
typedef
struct
__orxSTRUCTURE_t
{
orxSTRUCTURE_ID eID; /*
*< Structure ID : 4
*/
orxU32 u32RefCounter; /*
*< Reference counter : 8
*/
orxU32 u32Flags; /*
*< Flags : 12
*/
orxHANDLE hStorageNode; /*
*< Internal storage node handle : 16
*/
} orxSTRUCTURE;
一个ID,一个引用计数,一个标志量,一个存储节点的HANDLE。
Handle:
typedef void * orxHANDLE;
在C中也就用做于任何类型的指针。。。。。。。。。
在同样的头文件中,还有下面这个type枚举:
/*
* Structure storage types
*/
typedef
enum
__orxSTRUCTURE_STORAGE_TYPE_t
{
orxSTRUCTURE_STORAGE_TYPE_LINKLIST = 0
,
orxSTRUCTURE_STORAGE_TYPE_TREE,
orxSTRUCTURE_STORAGE_TYPE_NUMBER,
orxSTRUCTURE_STORAGE_TYPE_NONE = orxENUM_NONE,
} orxSTRUCTURE_STORAGE_TYPE;
但是基础结构中没有表示类型的变量,而handle到底表示什么类型的变量,就是这里面的几种了,list或者tree了,这个问题见下面的实现结构部分.
这里还看不出太多的东西,下面看看内部的实现结构:
/*
**************************************************************************
* Structure declaration *
**************************************************************************
*/
/*
* Internal storage structure
*/
typedef
struct
__orxSTRUCTURE_STORAGE_t
{
orxSTRUCTURE_STORAGE_TYPE eType; /*
*< Storage type : 4
*/
orxBANK *pstNodeBank; /*
*< Associated node bank : 8
*/
orxBANK *pstStructureBank; /*
*< Associated structure bank : 12
*/
union
{
orxLINKLIST stLinkList; /*
*< Linklist : 24
*/
orxTREE stTree; /*
*< Tree : 20
*/
}; /*
*< Storage union : 24
*/
} orxSTRUCTURE_STORAGE;
/*
* Internal registration info
*/
typedef
struct
__orxSTRUCTURE_REGISTER_INFO_t
{
orxSTRUCTURE_STORAGE_TYPE eStorageType; /*
*< Structure storage type : 4
*/
orxU32 u32Size; /*
*< Structure storage size : 8
*/
orxMEMORY_TYPE eMemoryType; /*
*< Structure storage memory type : 12
*/
orxSTRUCTURE_UPDATE_FUNCTION pfnUpdate; /*
*< Structure update callbacks : 16
*/
} orxSTRUCTURE_REGISTER_INFO;
/*
* Internal storage node
*/
typedef
struct
__orxSTRUCTURE_STORAGE_NODE_t
{
union
{
orxLINKLIST_NODE stLinkListNode; /*
*< Linklist node : 12
*/
orxTREE_NODE stTreeNode; /*
*< Tree node : 16
*/
}; /*
*< Storage node union : 16
*/
orxSTRUCTURE *pstStructure; /*
*< Pointer to structure : 20
*/
orxSTRUCTURE_STORAGE_TYPE eType; /*
*< Storage type : 24
*/
} orxSTRUCTURE_STORAGE_NODE;
/*
* Static structure
*/
typedef
struct
__orxSTRUCTURE_STATIC_t
{
orxSTRUCTURE_STORAGE astStorage[orxSTRUCTURE_ID_NUMBER]; /*
*< Structure banks
*/
orxSTRUCTURE_REGISTER_INFO astInfo[orxSTRUCTURE_ID_NUMBER]; /*
*< Structure info
*/
orxU32 u32Flags; /*
*< Control flags
*/
} orxSTRUCTURE_STATIC;
/*
**************************************************************************
* Static variables *
**************************************************************************
*/
/*
* static data
*/
static
orxSTRUCTURE_STATIC sstStructure;
这里的结构就没有以前那么清晰了,以前是看到结构大概就知道实现的。
orxSTRUCTURE_STATIC
的orxSTRUCTURE_STORAGE astStorage[orxSTRUCTURE_ID_NUMBER];
用于为每个structure结构提供bank,bank还分成两种,
一种是pstNodeBank表示的节点的bank。一种是pstStructureBank是结构本身的bank。
此结构的
union
{
orxLINKLIST stLinkList; /**< Linklist : 24 */
orxTREE stTree; /**< Tree : 20 */
}; /**< Storage union : 24 */
部分很明显与
orxSTRUCTURE_STORAGE_NODE结构对应,表示的是一个orxSTRUCTURE_STORAGE_NODE结构结构的list或者tree。因为根据Orx中list/tree的使用方法。(比较奇怪,见以前的文章
)
orxSTRUCTURE_STORAGE_NODE结构的第一个成员是
union
{
orxLINKLIST_NODE stLinkListNode; /**< Linklist node : 12 */
orxTREE_NODE stTreeNode; /**< Tree node : 16 */
};
正好符合要求。
然后这个节点结构的内容还包括:
orxSTRUCTURE *pstStructure; /**< Pointer to structure : 20 */
orxSTRUCTURE_STORAGE_TYPE eType; /**< Storage type : 24 */
难道是每个结构bank分配的内存指针最后都保存在这里面吗?
假如真是这样,那与
orxSTRUCTURE_STATIC
结构成员变量orxSTRUCTURE_REGISTER_INFO不是重复吗?
因为这个结构也包含:
orxSTRUCTURE_STORAGE_TYPE eStorageType; /*
*< Structure storage type : 4
*/
orxU32 u32Size; /*
*< Structure storage size : 8
*/
这个问题暂时留着,等下面看流程的时候再来验证。
然后orxSTRUCTURE_REGISTER_INFO这个注册信息结构中还有个update函数的指针,很突出,类型是:
/*
* Structure update callback function type
*/
typedef
orxSTATUS (orxFASTCALL *orxSTRUCTURE_UPDATE_FUNCTION)(orxSTRUCTURE *_pstStructure, const
orxSTRUCTURE *_pstCaller, const
orxCLOCK_INFO *_pstClockInfo);
一个结构注册后,每次还需要进行update?
哈哈,到这里,已经解答了我的疑惑,既然module与Structure都是用于总体的管理整个Orx的结构的,为啥还需要两个这样的组织管理方式?而且很多类还是属于module,structure两个组织结构管理的?而且,上面看到Structure的列表也说了,Structure更加倾向于游戏中具体的概念,module倾向于底层实现。到了这里,再加上Orx一贯的一切自动化的思路,Structure的核心作用就很明显了!那就是管理所有需要对象的创建及update!没错,与module管理所有module的依赖,初始化,退出一样,Structure主要就是管理创建新对象及Update,这个在Orx这个非典型的游戏引擎中非常重要。在大部分游戏引擎中,我们需要手动的写主循环,然后控制主循环,并将update从主循环中一直进行下去,同时手动创建对象,但是Orx是配置驱动的,我们通过配置创建了对象,创建了一堆的东西,然后就都不管了,全丢给Orx了,Orx就是通过Structure这样的结构来统一管理的,也就是说,Structure是Orx运转的基石。同时Structure与module的更明显不同也显现出来了,Structure管理的是对象,一个Structure的"子类"可以有很多个创建出来的对象,module是管理模块,每个模块就是唯一的一个全局对象,所以需要统一的进行初始化及退出处理。
知道了这个以后,再回头来看看Structure列表,什么感觉?很熟悉啊,原来都是config中能够配置自动创建的对象!
这也是为什么Orx会费很大精力将所有配置能够创建的对象集中在这个Structure体系中管理了,无论其对象最终是什么,在Orx中都需要对通过配置其进行创建,update,所以提炼出了这个最终的基类,并且对所有对象进行统一的管理。
同时,上面遗留的问题,也有了一些思路了,既然是用于update的,那么分配出来的对象不一定就一定马上update,所有才会有orxSTRUCTURE_REGISTER_INFO与orxSTRUCTURE_STORAGE中的重复,很明显,Orx是在某个结构REGISTER(注册后)才开始update的。
基本的思路已经清晰了,下面通过流程来验证一下:
因为viewport总是需要创建的,从它入手:
首先看viewport的结构:
/*
* Viewport structure
*/
struct
__orxVIEWPORT_t
{
orxSTRUCTURE stStructure; /*
*< Public structure, first structure member : 16
*/
orxFLOAT fX; /*
*< X position (top left corner) : 20
*/
orxFLOAT fY; /*
*< Y position (top left corner) : 24
*/
orxFLOAT fWidth; /*
*< Width : 28
*/
orxFLOAT fHeight; /*
*< Height : 32
*/
orxCOLOR stBackgroundColor; /*
*< Background color : 48
*/
orxCAMERA *pstCamera; /*
*< Associated camera : 52
*/
orxTEXTURE *pstTexture; /*
*< Associated texture : 56
*/
orxSHADERPOINTER *pstShaderPointer; /*
*< Shader pointer : 60
*/
};
符合前面
Structure
注释中说明的要求,也就是第一个结构是orxSTRUCTURE
类型的成员变量。我发现Orx最喜欢利用这样的技巧,list的node也是,tree的node也是,可能iarwain最喜欢这样使用C语言吧,不过的确很有用,此时__orxVIEWPORT_t
结构对象的指针与其第一个变量stStructure
的指针位置是完全一样的,也就是说,此指针可以直接作为一个orxSTRUCTURE
来使用,使用的时候,通过orxSTRUCTURE
类型中保留的type信息,又能还原整个对象的信息,保存的时候无论多少类型这样的对象的确只需要都保存orxSTRUCTURE
结构指针就行了。
orxViewport_Create
函数中,调用orxStructure_Create并加上自己的STRUCTURE_ID来创建了viewport。
/* Creates viewport */
pstViewport = orxVIEWPORT(orxStructure_Create(orxSTRUCTURE_ID_VIEWPORT));
这个函数虽然只有一句,但是包含的信息很多,orxStructure_Create函数就像前面说的那样,利用Structure的Bank和node的bank分别为Structure和node分配缓存。分配后直接添加在orxSTRUCTURE_STORAGE的list/tree中。
前面的orxVIEWPORT类似强转,但是其实不是,因为不会如此将一个指针直接转成一个结构(非指针)了。
#define orxVIEWPORT(STRUCTURE) orxSTRUCTURE_GET_POINTER(STRUCTURE, VIEWPORT)
#define orxSTRUCTURE_GET_POINTER(STRUCTURE, TYPE) ((orx##TYPE *)_orxStructure_GetPointer(STRUCTURE, orxSTRUCTURE_ID_##TYPE))
这里的关键是另一个函数:
/*
* Gets structure pointer / debug mode
* @param[in] _pStructure Concerned structure
* @param[in] _eStructureID ID to test the structure against
* @return Valid orxSTRUCTURE, orxNULL otherwise
*/
static
orxINLINE orxSTRUCTURE *_orxStructure_GetPointer(const
void
*_pStructure, orxSTRUCTURE_ID _eStructureID)
{
orxSTRUCTURE *pstResult;
/*
Updates result
*/
pstResult = ((_pStructure != orxNULL) && (((orxSTRUCTURE *)_pStructure)->eID ^ orxSTRUCTURE_MAGIC_TAG_ACTIVE) == _eStructureID) ? (orxSTRUCTURE *)_pStructure : (orxSTRUCTURE *)orxNULL;
/*
Done!
*/
return
pstResult;
}
传进一个orxSTRUCTURE的指针(orxStructure_Create的返回值),然后传出一个新的orxSTRUCTURE结构指针,再进行强转,感觉很怪异。
因为事实上,就上面的分析,只需要提供一个orxSTRUCTURE结构的指针指向的的确是一个"子类"对象的内存,是可以直接强转使用的。
所以这里的确怪异。
从orxSTRUCTURE_MAGIC_TAG_ACTIVE这个怪异的宏定义入手:
/*
* Structure magic number
*/
#ifdef __orxDEBUG__
#define orxSTRUCTURE_MAGIC_TAG_ACTIVE
0xDEFACED0
#else
#define orxSTRUCTURE_MAGIC_TAG_ACTIVE
0x00000000
#endif
可见是为了debug准备的。并且意图是在debug的时候检验结构的eID成员变量,debug时发现此eID实际指向的是一段未分配内存(野指针时),能够返回空。
那这个0xDEFACED0
是怎么来的呢?magic嘛。。。。我也不知道,可能是作者在debug的时候特意打上去的标记,因为与主流程无关,这里不深究了。
另外,对于viewport来说,我发现在Orx中其并没有update函数,所以在一个真正的viewport创建出来的时候就先通过
eResult = orxSTRUCTURE_REGISTER(VIEWPORT, orxSTRUCTURE_STORAGE_TYPE_LINKLIST, orxMEMORY_TYPE_MAIN, orxNULL);
注册了,最后的注册的update函数是orxNULL,应该就表示不需要update了吧。
下面看一个需要update的,比如animpointer。
在
orxObject_UpdateAll
函数中
会遍历所有的object:
/* For all objects */
for(pstObject = orxOBJECT(orxStructure_GetFirst(orxSTRUCTURE_ID_OBJECT));
pstObject != orxNULL;
pstObject = orxOBJECT(orxStructure_GetNext(pstObject)))
并且,还会:
if
(pstObject->astStructure[i].pstStructure != orxNULL)
{
/*
Updates it
*/
if
(orxStructure_Update(pstObject->astStructure[i].pstStructure, pstObject, pstClockInfo) == orxSTATUS_FAILURE)
{
/*
Logs message
*/
orxDEBUG_PRINT(orxDEBUG_LEVEL_OBJECT, "Failed to update structure #
%ld
for object <
%s
>."
, i, orxObject_GetName(pstObject));
}
}
注意,这里的结构的update是pstObject
调用的。也就是说,前面配置及自动化的那么多的部分,事实上并不是直接由Orx底层的clock直接调用的,而是由object来驱动的。
这里通过遍历Structure结构中的update函数,完成了每个object里面需要update的部分的update,因为Orx的配置几乎是以object为基础的,所以这样设计非常合理。
同时,这里也真实的再现了面向对象的基础需求之一,对不同的对象使用相同的接口,并且不关心具体是哪个对象。。。。。。。这里object就不关心内部那一个Structure指针的数组变量中每个变量具体存储的真实Structure类型了,只需要用同一的update回调即可。。。。。
到了这里,Orx的主要组织结构module和Structure都看过了,底层的基础结构和模块也看过了。整体的Orx主干已经清晰了,具体的每个Structure,module是怎么实现的,暂时就不看了,需要的时候看一看就很清楚了。
原创文章作者保留版权 转载请注明原作者 并给出链接
write by 九天雁翎(JTianLing) -- www.jtianling.com
阅读全文....