本文译自
orx tutorials
的对
象(object)
。phpxer
译,九天雁翎 (博
客
)修订。最新版本见Orx
官方中文Wiki
。
本文转自phpxer的博客
。原文链接在:http://blog.feihoo.com/2010/07/orx_tutorial_cn_object.html
望有新人能够加入这个翻译者的队伍,早日将Orx的WIKI页中文化。有兴趣的请加入qq群73063577,并与我取得联系,防止重复翻译。
Object (对象)教程
总结
由于orx是数据驱动的,我们只需要两行代码创建一个viewport(视口)和一个object。它们的所有属性都定义在配置文件
(01_Object.ini)中。
Viewport关联到一个按照配置文件中的信息隐含创建的camera(摄像头)。在配置文件里,你还可以设置它们的大小,坐标,对象的颜色,缩
放,旋转,动画,物理属性等等。你甚至无需增加一行代码就可以让任何的配置获得随机值。
在后面的一个示例中我们将看到如何使用一行代码生成复杂的object体系甚至整个 scene(场景)(所有的背景对象和普通对象)。
现在,你可以尝试取消01_Object.ini中某些行的注释,自己尝试一下,然后再继续学习这个教程。完整的选项列表请查看
CreationTemplate.ini。
详细说明
创建一个object是相当简单的。不过,我们首先需确保已经加载了定义了所有object(对象)的属性的配置文件。我们还要通过
viewport/camera组合显示创建好的object(对象)。
不要慌张!所有这些都很容易。
在这篇教程中,我们将加载一个位于父目录中的配置文件。正如你可能想到的,在所有的可执行程序都根据其构建类别(mingw, msvs2005,
msvs2008, 等)位于各自的子目录的情况下,我们不打算在每个地方重复同样的配置文件。1)
在我们的例子中,加载配置文件使用类似下面这行代码的方式实现:
orxConfig_Load(”../01_Object.ini”);
然后我们创建viewport(视口)。注意 camera的创建是按照为这个viewport预置的配置信息自动完成的。
orxViewport_CreateFromConfig(”Viewport”);
我们差不多完成了。现在我们只需要创建 object!
orxObject_CreateFromConfig(”Object”);
就这样了!object(对象)已经创建,并且由于在camera的视觉平截体(frustum)内,将会被显示出来。
现在,因为我们使用Orx默认的启动器,我们需要申明我们的插件入口点(这里是我们的Init函数)。这可以使用一个宏很容易地实现。
orxSTATUS Init(){...}
orxPLUGIN_DECLARE_ENTRY_POINT(Init);
因为orx是数据驱动的,我们不需要手动加载任何数据,例如一个sprite(精灵)。一切都由数据管理器为我们搞定,它会确保sprites不在
内存中重复并在其不再使用时自动释放的
如果你查看配置文件,在[Object]这一节,你将看到你可以设定所有的对象属性,例如 graphic
(sprite),锚点,颜色,透明度,物理属性,坐标,旋转,缩放,tiling(平铺)(重复),动画,视觉特效,等等。
不要担心,这一切都将在后面的教程中讲到。
现在我们拥有了一个object(对象),我们需要学习如何与之交互。这将我们带入第二个教程:clock.
资源
-
源代码: 01_Object.c
- 配置文件: 01_Object.ini
1) 不过,如果你的配置文件名字与可执行文件匹配并且在同一个文件夹下,它将被自动加载。
阅读全文....
本文译自
orx tutorials
的首
页(main)
。phpxer
译,九天雁翎 (博
客
)修订。最新版本见Orx
官方Wiki中文教程
。转载自:phpxer的博客
。原文链接在http://blog.feihoo.com/2010/07/orx_tutorial_cn_basic.html
。
希望有新人能够加入这个翻译者的队伍,早日将Orx的WIKI页中文化。有兴趣的请加入qq群73063577,并与我取得联系,防止重复翻译。
教程
本教程主要包含Orx的基础和
高级教程。Orx 是一个开源、跨平台、轻量级、数据驱动的2D游戏引擎。
安装
这些教程演示了如何设置不同的
编程环境(IDE)
来运行
orx
1)
。
本节将要介绍orx的基础知
识。
你可以从
这里
下载Windows(mingw,
msvs2005 & msvs2008). Linux 和 MacOS X下的
可执行文件
(包括项目文件,数据和源码)。
前九个基础教程(#1 –
#9)使用默认的orx启动程序为
基础
(underlying
layer),这样易于快速测试/制作原型
2
。
它们被编译成运行时加载(在命
令行
3)
上
或配置文件中指定它们的名字)的动态连接库。
此外,下面的内容
4)
解释了哪些行为是由默认的orx.exe/orx 启动程序提供的。
这是一个基础的C教程。
由于我们在本教程中使用默认的可执行文件,下面
的代码将以插件的方式加载和执行。
另外,一些
基础设施
有
主执行文件
为我们处理。
首先,它会加载所有可用的插件和模块。如果你只
需要其中的一些,最好编写你自己的
可执行文件
而不是插件。这部分包含在
后面的教程
中。
主执行文件还处理下面这些
键盘输入
:
* F11 是
纵向对齐切换
* Escape 退出
* F12 截屏
* 退格键(Backspace)
重新载入全部配置文件
如果有
orxSYSTEM_EVENT_CLOSE事件发生,程序也会退出。
不过,如果使用
orx作为传统库构建你自己的可执行文件当然也是可以的(也很容易做到)。在
教程 #10
(使用C++编写) 和
教程 #11
(使用 C编写)。
教程 #10
还演示了如何使用orx编写C++代码
5)
。
同样地,你可以用任何可与C连接的语言编写程序。
在将来的发布中将会为某些常见
语言提供封装。如果你想编写这种封装库,为orx做贡献,请通过
论坛
联系我们。
当前提供的基础教程列表:
- [C]
object
- [C]
clock
- [C]
frame
- [C]
animation
- [C]
viewport &
camera
- [C]
sound & music
- [C]
fx
- [C]
physics
- [C]
scrolling
- [C++]
stand alone &
localization
- [C]
spawner &
shader
下面这些教程由社区创建,它们
是了解如何使用 orx的不错的资源,可以在这里寻找到对一些简单问题的解答。
1)
所有的IDE都是免费可以从英特网上下载的。
2)
one line for the
whole initialization, no main function to write, no loop to handle
用一行代码完成初始化,不需要写main函数,
没有
循环
要
处理
3)
另提供了 .bat/.sh
脚本方便启动所有示例
4)
你将在在所有教程的源文件的开始处看到这些内容
5)
Orx本身使用C编写
阅读全文....
write by 九天雁翎(JTianLing) -- www.jtianling.com
讨论新闻组及文件
虽然很早就想用做一个完整游戏来完成此教程,但是在做什么游戏的问题上很纠结,太大太好的游戏太费精力,太小的游戏又不足以展示Orx的特点,选来选去也没有自己感觉最合适的,最后还是选择打砖块吧,此游戏虽然不能展示Orx的全部特点,但是很好的展示了其内嵌物理引擎的特点。因为Orx内嵌Box2D物理引擎,所以在游戏中使用物理,从来没有这么方便过,也许,哪天我该写一篇用Cocos2D+Box2D的类似文章来做比较。
Orx 中的Object概述
在Orx中一个Object到底表示什么?简单的说,表示一切。一切有形的无形的,可见的不可见的东西。在Orx中,所有所有的概念全部归结于 Object。所有其他的东西,都是Object的属性。包括通常概念里面的sprite,animation等等,在Orx中还包括特效(fx),物理属性等。在几乎所有的2D游戏引擎中,几乎都是是Sprite为基础的,而在Orx中,是以Object为基础的。
显示一个 Object
在几乎所有的2D游戏引擎中,几乎都是是Sprite为基础的,所以最基本的操作都是显示一个Sprite,那么,换到Orx中,最基础的那就是显示一个 Object了。
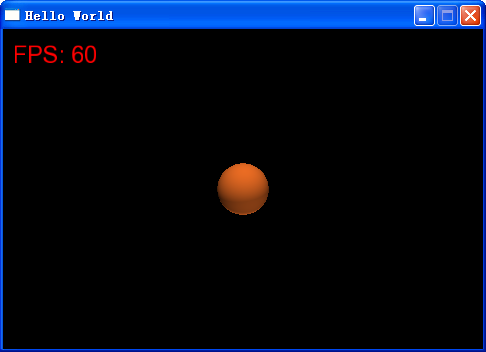
其实,在原来《站在巨人的肩膀上开发游戏(2) -- Orx入门引导及Hello World》中,我们已经显示过一个 Object了,没错,那个Hello World的文字就是一个Object.........只不过其图形是显示文字而已。所以,我们创建Hello World的时候,调用的接口是orxObject_CreateFromConfig。
要将其换成显示图形,只需要改配置,将其显示成一个图形即可,因为是做打砖块游戏,这里,我显示一个球。(这里的资源全部来自于《How To Create A Breakout Game with Box2D and Cocos2D Tutorial》)顺便可以将Orx版本的程序与Cocos2D + Box2D(另外一个我非常喜欢的组合)做比较。
原代码的改动仅出于代码可读性考虑,将HelloWorld改为Ball,Orx的特点之一,不改代码,你甚至可以使用原来编译好的Hello World程序(必须是教程1老的那个,教程2新的那个我做了特殊处理),只需要将新的配置中的Ball改为HelloWorld即可。当然,出于可读性,这样做不自然,但是我还是提及这样做的可能性。
新添加配置如下:
[Ball]
Graphic = BallGraphic
Position = (0.0, 0.0, 0.0) ;球所在的位置
[BallGraphic]
Texture = data/ball.png ;球图形的png文件的位置
Pivot = center
原来的代码如下:
// Init game function
orxSTATUS GameApp::InitGame()
{
orxSTATUS result = orxSTATUS_SUCCESS;
// Creates viewport
if ( orxViewport_CreateFromConfig("Viewport") == NULL ) {
result = orxSTATUS_FAILURE;
}
if (orxObject_CreateFromConfig("Ball") == NULL) {
result = orxSTATUS_FAILURE;
}
// Done!
return result;
}
然后,就能显示出个球了。(显示个球-_-!)
就这么一个Object显示出来以后,就可以继续自由发挥了,很多的想象空间。
比如Scale = XXX调整球的大小。
比如Speed = (xxx, xxx, xxx) 给球初始速度,
(上面的属性都添加到 [Ball]段)
按照上面的方法,按打砖块游戏的特点,添加砖块及paddle。
配置:
[Ball]
Graphic = BallGraphic
Position = (0.0, 180.0, 0.0)
[BallGraphic]
Texture = data/ball.png
Pivot = center
[Paddle]
Graphic = PaddleGraphic
Position = (0.0, 230.0, 0.0)
[PaddleGraphic]
Texture = data/paddle.png
Pivot = center
[Blocks]
ChildList = Block1 # Block2 # Block3 # Block4
[Block1]
Graphic = BlockGraphic
Position = (-50.0, -30.0, 0.0)
[Block2]
Graphic = BlockGraphic
Position = (50.0, -30.0, 0.0)
[Block3]
Graphic = BlockGraphic
Position = (-50.0, 30.0, 0.0)
[Block4]
Graphic = BlockGraphic
Position = (50.0, 30.0, 0.0)
[BlockGraphic]
Texture = data/block.png
Pivot = center
代码:
// Init game function
orxSTATUS GameApp::InitGame()
{
orxSTATUS result = orxSTATUS_SUCCESS;
// Creates viewport
if ( orxViewport_CreateFromConfig("Viewport") == NULL ) {
result = orxSTATUS_FAILURE;
}
if (orxObject_CreateFromConfig("Ball") == NULL) {
result = orxSTATUS_FAILURE;
}
if (orxObject_CreateFromConfig("Paddle") == NULL) {
result = orxSTATUS_FAILURE;
}
if (orxObject_CreateFromConfig("Blocks") == NULL) {
result = orxSTATUS_FAILURE;
}
// Done!
return result;
}
代码实在就是没有太多好说的了,在Orx中,永远是配置复杂,代码简单。说说配置中的新东西,我在这里用
[Blocks]
ChildList = Block1 # Block2 # Block3 # Block4
的形式+一行创建Blocks的代码,来完成了4个砖块的创建。这是Orx中使用子列表的一种方式。
效果如下:(我把窗口大小也改了)

是不是有那么一点意思了?
到目前为止,我们学到什么了?4行配置。。。。。。。。。。且只有Graphic加Texture算是新内容。只要这些,你通过position就可以完成你想要的任何图形布局了。
当然,其实远远不止这些,请参考Orx的WIKI获取更多的信息:
物理的加入
好了,现在是添加真的游戏内容的时候了。光是静态图形可做不了游戏。
在打砖块的游戏中,很重要的就是球的碰撞,反弹,以及碰撞的检测了。由于Orx中内嵌了Box2D引擎,我们能够很方便的使用,我多次提到是内嵌,而不是外挂,不是如Cocos2D那种仅仅包含一个Box2D,然后需要你调用Box2D的API去完成的那种,事实上,你可以根本不知道Box2D是啥。(其实个人感觉,了解Box2D的相关概念是必要的,不然怎么知道各个属性应该怎么配置啊)
首先,物理世界的加入:
[Physics]
DimensionRatio = 0.1
WorldLowerBound = (-300.0, -300.0, 0.0)
WorldUpperBound = (300.0, 300.0, 0.0)
这是必须的,似乎属于Box2D为了优化而添加的,Orx为了灵活,没有自动的去配置这些属性,一般而言,将其设为包含整个游戏屏幕即可。(稍微大一点点)配置的是一个矩形的左上角和右下角。(注意Orx的坐标系啊)
然后,为各个物体添加物理属性,最主要的是Body段的属性:
[Ball]
Graphic = BallGraphic
Body = BallBody
Speed = (0, -40, 0)
Position = (0.0, 180.0, 0.0)
[BallGraphic]
Texture = data/ball.png
Pivot = center
[BallBody]
Dynamic = true
PartList = BallPartTemplate
[BallPartTemplate]
Type = sphere;
Friction = 0.0;
Restitution = 1.0;
Density = 1.0;
SelfFlags = 0x0001;
CheckMask = 0x0001;
Solid = true;
注意Ball的中添加了一个Body = BallBody,然后所有的物理部分都写在了BallBody和BallPartTemplate中。先说明一下,之所以我把part叫template,而且Orx的作者添加了这样一个新的段来表示物理部分,包括命名为part,是因为Orx允许一个body有多个part组合成一个object的物理。这在某些时候也极为有用。比如希望有个组合图形,一个part无法表示的时候。
至于各个物理的属性的含义,推荐先去了解一下Box2D 的各个定义。要图省事,看看Orx的说明也行。
然后,如法炮制,基本的意思就有了。
[Paddle]
Graphic = PaddleGraphic
Body = PaddleBody
Position = (0.0, 230.0, 0.0)
[PaddleGraphic]
Texture = data/paddle.png
Pivot = center
[PaddleBody]
Dynamic = false
PartList = PaddlePartTemplate
[PaddlePartTemplate]
Type = box;
Friction = 0.0;
Restitution = 1.0;
Density = 1.0;
SelfFlags = 0x0001;
CheckMask = 0x0001;
Solid = true;
[Blocks]
ChildList = Block1 # Block2 # Block3 # Block4
[Block1]
Graphic = BlockGraphic
Body = BlockBody
Position = (-50.0, -30.0, 0.0)
[Block2]
Graphic = BlockGraphic
Body = BlockBody
Position = (50.0, -30.0, 0.0)
[Block3]
Graphic = BlockGraphic
Body = BlockBody
Position = (-50.0, 30.0, 0.0)
[Block4]
Graphic = BlockGraphic
Body = BlockBody
Position = (50.0, 30.0, 0.0)
[BlockGraphic]
Texture = data/block.png
Pivot = center
[BlockBody]
Dynamic = false
PartList = BlockPartTemplate
[BlockPartTemplate]
Type = box;
Friction = 0.0;
Restitution = 1.0;
Density = 1.0;
SelfFlags = 0x0001;
CheckMask = 0x0001;
Solid = true;
特别需要注意的是,Orx的设计上常常会让人感觉很多时候一个段的东西拆了几个段,写起来很麻烦,但是每个段都是可以复用的,比如此例中,所有的Block都共用一个Body。所以作者从长远考虑才这样做。
然后,再给Ball 一个速度。你就能够看到物理的作用了。球从paddle反弹到block再反弹到paddle。带角度。。。。。。。。。
碰撞检测
打砖块的游戏要求球碰到砖块时砖块消失的,这个需要做碰撞检测,这在Orx中也是很简单的,需要进行物理的Event响应,这是个新内容。
首先,初始化的时候,添加关注的事件。
orxEvent_AddHandler(orxEVENT_TYPE_PHYSICS, GameApp::EventHandler);
这个没有什么好说的,别忘了就行。
然后,就是在注册函数中物理的响应了,此例中是GameApp::EventHandler。
// Event handler
orxSTATUS orxFASTCALL GameApp::EventHandler(const orxEVENT *_pstEvent)
{
orxSTATUS eResult = orxSTATUS_SUCCESS;
if(_pstEvent->eType == orxEVENT_TYPE_PHYSICS) {
if( _pstEvent->eID == orxPHYSICS_EVENT_CONTACT_ADD ) {
/* Gets colliding objects */
orxOBJECT *object_recipient = orxOBJECT(_pstEvent->hRecipient);
orxOBJECT *object_sender = orxOBJECT(_pstEvent->hSender);
string recipient_name(orxObject_GetName(object_recipient));
string sender_name(orxObject_GetName(object_sender));
if(recipient_name == "Ball" && sender_name != "Paddle") {
orxObject_Delete(object_sender);
}
}
}
// Done!
return orxSTATUS_SUCCESS;
}
有了代码后,其实基本上意思都很明显了,先判断事件的类型,然后判断事件的ID(其实相当于某类型事件中的子类型),这里判断的是物理的contact_add,表示有碰撞(外国人喜欢说有接触?)产生的时候。然后通过名字去判断两个物体是什么。这里没有考虑效率,直接用名字来判断了(事实上可以通过设定 userdate,然后通过ID判断),再进一步,为了方面直接用std::string而没有通过strcmp了。
判断被推开的物体是球,而且还不是paddle推开的,那么就肯定是block了,此时用orxObject_Delete将其删除,实现打砖块的消除效果。
需要完善的部分
游戏其实基本成型了,剩下的,就是给游戏加个边框,(这个都不需要我额外讲方法了)不然球飞出去了,然后就是操作部分了,下一节再讲。
原创文章作者保留版权 转载请注明原作者 并给出链接
write by 九天雁翎(JTianLing) -- www.jtianling.com
阅读全文....
Orx作者iarwain亲自录制,品质保证,非Youtube,中国可流畅播放。
- Part1: setup and
build(设置及构建)
- Part2:
simple object display(简单的物体显示)
- Part3: advanced object properties(高级物体属性)
- Part4: simple visual FX(简单的特效)
-
Part5: spawner
combined with FX(加特效的spawner) spawner不知道怎么翻译,大概类似于一个游戏中的物体创建发生器
- Part6: more spawner controls(更多的spawner控制)
- Part7: config override
and release/debug builds(配置覆盖和release/debug构建)
- Part8: final summary(总结)
因为有些老,我都从来没有看到过。。。。。。。。作者不保证全部的内容现在都还有效(新版的API,Config可能有些变化),但是,对Orx有个大概的了解是肯定没有问题。对于不想一行一行阅读英文教程的人也是个福音吧。
有意思的是,整个视频,没有一点声音,但是作者还是非常想表达自己的观点,那么怎么办?举个例子。在final summary中,作者连续选中唯一的两行createfromconfig代码N次,然后不停的改配置,就是告诉你,我只有2句代码,通过配置能实现什么效果,从一个小女孩(iarwain惯用),到旋转的气泡,到与气泡一起旋转的小女孩,作者没有改过一行代码,一直使用一个编译好的程序,仅仅通过notepad++来编辑配置。那就是iarwain的总结,估计其一直以此为自豪,所以在VS中高亮选择那么两行代码,其实,整个过程,VS几乎就是摆设,因为从来没有用到过。
阅读全文....

作为一个没有任何盈利并且code for fun的项目Orx,iarwain用在Ubisoft工作之余,几乎每天没有间断过的维护着。。。。。。。。。从代码提交记录上来看,这么积极的维护的开源项目,真的是少有了。。。。。。。。。。
想到自己,真是惭愧啊。。。。。。。。。
因为Orx的数据驱动的特点,因为iarwain的勤奋和热心,我也真是喜欢多多学习使用Orx,因为这是一个用心在做的项目。
甚至,同期全职上班的人,用上班时间做的东西,将提交记录总结出来,也不见的有iarwain用业余时间做的这么多吧?他还常说他很忙,需要带孩子。。。。我的天哪。。。。。。。。。。。
阅读全文....
write by 九天雁翎(JTianLing) -- www.jtianling.com
讨论新闻组及文件
Orx作品展示
一个相对成熟的引擎背后不可能没有相对成熟的游戏。这点我深信不疑,毕竟引擎不是闷着脑袋在家里开发的,而且通过开发游戏来促进的。相对来说,目前还没有发现用Orx制作的非常大型的精良的游戏,这点也说明了Orx的不成熟,我一点都不忘提及,Orx的确还不成熟,我只能说,iarwain的开发思想很好,Orx的设计很有意思,用于开发一款游戏的速度也很快,很灵活。但是,这里还是有一些用Orx制作的小作品,起码可以看出,Orx可以做什么,已经做到什么效果。同时,也对对于Orx不了解,没有信心的人一点新的关于Orx的信息。
这些作品在Orx的论坛上都有,但是鉴于很多时间已经很久,并且语言的原因,没有人去深挖或者寻找了,我这里将一些我见到的提出来,给大家看看。
其一:Mushrooms Stew
此作品由Orx目前的主要维护者iarwain自己主要负责开发,甚至还实现了一个小规模的level editor。
该游戏讲述的是一个蘑菇间的故事。。。。。呵呵,动画效果其实很不错,虽然个人感觉游戏性薄弱了一点,但是还算是值得一玩。
原论坛帖子地址在此
。开源发布
。因为Orx的跨平台特性,你可以在Windows,Macos,Linux上玩到。
截图:



编辑器截图:

其二:Drops
一个有趣的游戏,与音乐相结合。特别是一些效果处理的非常好,比如选择颜色那个动画,相当的酷。整个工程完全用C语言写的,也算是怎么用C语言+Orx做游戏的一个非常好的例子。
论坛原址
,开源发布
。
截图:
其三: DragonCube
一个有非常好的动画效果,非常有意思特性的Demo,论坛原址
这里先提出论坛原址,因为想说说这个Demo背后的故事,帖子名叫First steps, first project
,这是 Blarg
,一个iarwain说的原本是做Flash的设计师,原来根本不是程序员,在看了Orx的教程后,仅仅是通过模仿Orx教程中的一条一条特性,前后只用了一周多的时间(从帖子也可以看出来iarwain所说属实)开发出来的。。。。。。。。闭源发布
。
因此,我感觉那是有非常非常让人诧异和惊艳的效果,呵呵,你说那是用Flash做的,估计也没有人不相信。。。。。。。。推荐每一个准备学习Orx的人看看,一个尚且不是程序员的人,两周之内能用Orx做到什么程度。。。。。。。。。
不清楚为啥在csdn上发布的时候我的图先前还在,为啥到后来丢失了。不可理喻。。。。。。。。。
原创文章作者保留版权 转载请注明原作者 并给出链接
write by 九天雁翎(JTianLing) -- www.jtianling.com
阅读全文....
write by 九天雁翎(JTianLing) -- www.jtianling.com
讨论新闻组及文件
前言
在上一节构建了一个用Orx完成的Hello World程序,想起以前有的用N中方式完成Hello World程序的例子,也许这个算是其中最最复杂的了。有个问题问题在于Orx中文字的输出为了与Object一致,所以弄的非常麻烦,毕竟简单的文字完全没有Object那么多属性需要配置。(参考前一节)事实上,经过与iarwain的沟通,最后确认了简化的办法,那就是写自己的函数做为包装。做为前置条件,先学习Orx中config相关API的使用。
配置相关的API
在Orx的WIKI上有个详尽的页面描
述此API。主要的API以orxConfig_SetXXX及orxConfig_GetXXX组成,比较简单。不举太多例子了。
section的处理也比较简单,push,pop用于使用某个section并且还原,seclect用于选择某个工作的section,但是有个特别的地方,这些API会在section不存在的时候,创建section。
这也是我需要的。
文字输出的简化
下面就开始文字输出的简化,上一节分析了在Orx中输出文字为什么那么复杂,主要原因在于文字模拟了Object的创建,并享有Object的所有其他功能,所以一个简单的文字属性被分成了3段,这样就变得复杂了,我的思路是将所有的属性都放在一段中,并且还是走原来的路,按照Object的创建方式来创建,事实上,因为orxObject_CreateFromConfig的实现比较复杂,就不重复其原有步骤了,我通过从配置文件中的一段配置,动态构建出此API需要的三段,然后再用原API来创建,这样虽然效率上可能会低一点,但是最大程度的利用了原有函数。
简单的例子,原有的HelloWorld例子中,HelloWorld的配置就有3段,如下:
[HelloWorld]
Graphic =
HelloWorldGraphic
[HelloWorldGraphic]
Text =
HelloWorldString
Color =
(255.0, 0.0, 0.0)
[HelloWorldString]
String =
"HelloWorld"
事实上,我们需要的有效内容就只有2个
Color =
(255.0, 0.0, 0.0)
String =
"HelloWorld"
也就是说,我希望通过
[HelloWorld]
Color =
(255.0, 0.0, 0.0)
String =
"HelloWorld"
这样的配置,就能达到原有的效果。想想,7行配置,结果只有3行有用,其他4行都是浪费的无谓link和section,怎么说都无法忍受。为了完全还原原有效果,并且使其名字也能一样,只需要这样使用Orx的配置API即可。
orxOBJECT *CreateText(orxSTRING _zTextSection)
{
orxConfig_PushSection(_zTextSection);
orxConfig_SetString("Graphic"
, _zTextSection);
orxConfig_SetString("Text"
, _zTextSection);
orxOBJECT *pstReturn = orxObject_CreateFromConfig(_zTextSection);
orxConfig_PopSection();
return
pstReturn;
}
也就是说,通过将需要的Graphic和Text段都连接到自身,这样的config使用方法的想法,完全来自于iarwain.......我只能说,简化了太多太多东西,小小的INI配置,竟然能够玩弄的这样出神入化,可能是MS都无法想象到的。。。。。。。。。。。。。。
进一步学习
其实在Orx中普通的文字与Object共享了太多的东西,讲的太多,就会出现我前面讲的情况,因为讲解一个API而贯穿了整个Orx,这里仅仅提出几个特别的配置来说明。(虽然说是特别的配置,但是并不是对文字特别,也完全适用于普通的object,仅仅表示比较有用)
位置
首先,Position属性,表示位置。提到Position,又得将Orx的世界坐标系讲一讲,因为比较特殊。
Orx作为一个2D引擎,没有完全的使用屏幕坐标系,而是将屏幕坐标系移到了屏幕的中心点,(严格来说是创建viewport的中心点,以下都以此方式表述)也就是说,以屏幕中心点为原点,右边为X的正轴,下边为Y的正轴。
并且,因为Orx使用了Z buffer来解决遮挡的问题,还有Z轴坐标,Z轴坐标是从屏幕外指向屏幕内的。也就是屏幕外为负,屏幕内为正。
起码,在默认情况下,Orx的世界坐标就是这样。于是,Position的使用方式来了。指定坐标就可。
比如,原来我没有指定任何Position,那么就默认在原点创建了文字,我现在指定到-100,-100,就表示文字显示在离屏幕中心点,左100像素,上100像素的位置显示文字。如下图:
中心点
其实,对于文字来讲,有很多排版问题。比如向左对齐,向右对齐啥的,对于object来说就是中心点的问题。这里文字可以利用中心点来完成排版。当然,多行文字的问题就更加复杂了,需要手动排版。首先看属性Pivot
Pivot = center(+truncate|round)|left|right|top|bottom|[Vector]; NB: Truncate and round will adjust pivot values if they are not integers; z is ignored for 2D graphics;
将HelloWorld的配置设为下面这样时:
[HelloWorld]
Color =
(255.0, 0.0, 0.0)
String =
"HelloWorld"
Position =
(0.0, 0.0, 0.0)
Pivot =
center
显示效果如下图:
与没有设定中心点时比较一下:
可以发现,默认的时候,中心点是在左边的。可以选择配置的选项在上面的说明中都有了,并且允许组合,比如left top, left bottom,天哪,不可思议吧。。。。。。。。
甚至,你可以缩放和对其富裕初速度。。。。。。。。。
[HelloWorld]
Color =
(255.0, 0.0, 0.0)
String =
"HelloWorld"
Position =
(0.0, 0.0, 0.0)
Pivot =
left + bottom
Speed =
( 10.0, 0.0, 0.0 )
Scale =
2.0
大家自己去尝试吧,要知道,你可以将HelloWorld显示成各种各样的样子,却不用改变一行代码,也不用再次编译程序了,只需要改变配置。。。。。。。现在还没有好用的编辑器,很难想象,做个好用的编辑器后Orx会怎么样。。。。。。。。。。。。
原创文章作者保留版权 转载请注明原作者 并给出链接
write by 九天雁翎(JTianLing) -- www.jtianling.com
阅读全文....
write by 九天雁翎(JTianLing) -- www.jtianling.com
讨论新闻组及文件
前言
关于Orx的使用,iarwain自己写过一系列非常详细的教程 ,推荐每个学习Orx的人阅读之。此外,学习Orx的热心人士Grey也写过一个小教程:Grey's tutorials 。
开始写本系列的时候,不打算是上述教程的翻译,(iarwain表示很期待有人将其翻译成中文。。。。。有意向的可以与我联系,我会尽可能的提供帮助,虽然我对Orx的了解并不算透彻),也不准备重复上述教程中提到过的东西,也不是以替代上述教程为目的。想以完成实际的一个游戏为脉络,但是具体是以Orx的使用为主,(那么会偏重于各个配置),还是以Orx的API使用为主,或者探求Orx的内部,探寻实现原理,在这上面笔者比较矛盾。。。。。。。。。唉。。。写点东西纯属个人学习过程中的副产品,个人爱好而已,有的时候想法太多反而混乱,很想没有拘束的乱写一气,想到哪写到哪,但是又怕写的像当年边学边写的《Win32 OpenGL系列 》一样乱七八糟,错误百出。。。。。。。推荐所有人看过原iarwain教程并对Orx有一定了解后再看本系列文章,不然难说看完后我俩谁更混乱。本系列仅仅作为一个完整的Orx游戏制作参考+一些源码导读吧。
版本选择
在原来的《站在巨人 的肩膀上开发游戏(1) -- orx 库简单介绍 》中已经简单介绍过Orx了。
因为最近orx更新较快,但是API已经稳定,对于Win32平台,这里我推荐使用的是iarwain(Orx主要维护者)发布的稍微老一点的稳定版,orx1.1 是iarwain编译好的版本,可以拿来就用。 此版本有着较稳定的对Win32平台的支持。 作者还发布过1.2的beta版本 在此版本中,正式提供了对IPhone的支持。这里有SVN上的最新版 ,大家可以到http://orx.svn.sourceforge.net/viewvc/orx/trunk/上去下载,或者,用svn checkout https://orx.svn.sourceforge.net/svnroot/orx /trunk,这些最新的版本虽然添加了新的对IPhone,IPad的支持,但是就我在Win32试用的情况来看,还是有很多不稳定的情况,甚至有一次我编译都失败了,作者也正在将orx从SFML迁移到SDL,这也是个较大的工程,所以,我个人还是推荐大家暂时使用作者发布的1.1版本(PC)或原1.2的beta版本(IPhone),等待作者发布正式的1.2版本时再去使用新版本。iarwain曾经预计在5月末期发布orx1.2,不过因为iarwain突然想要添加一些新的功能 ,延期了,现在iarwain预计在6月下旬发布1.2版本,他说,"very soon now...."。
工程建立
我不希望所有的教程都像原来的Orx教程一样,仅仅是通过动态plugin的方式或者仅仅包含Orx Lib的方式,我希望教程与Orx源代码在一起,方便debug 进Orx的源代码和做游戏时查看Orx的源代码。这里我自己选择的是orx1.1的源代码版本 。然后,我的所有教程源代码 都会在Google Code的上托管。大家按需checkout,我还是使用了mercurial 。
工程创建方面的知识本来是不与Orx特别相关的,这里仅仅提到几点特别的地方,工程中SDL的部分在1.1中并没有使用,这是iarwain将来的1.2版本使用的。Orx本身的源代码有好几个选项,这与Orx支持的一些特殊功能有关,使用时需要特别注意自己需要的到底是什么,比如我上面的工程使用的就是Embedded Dynamic Debug/Release。另外,因为SDL和SFML库的版权问题,(LGPL)推荐使用Embedded Dynamic Debug的方式,这样你才可以闭源发布自己的软件。而在IPhone平台,iarwain没有使用SDL,所以你可以完全包含Orx并闭源发布。
在https://jtianling-orx--template-1-1.googlecode.com/hg/上,就是一个附带orx,box2d源代码的工程,(也包含了所有必要的lib和dll)可以很方便的进行调试。修改好工作路径后,就可以直接编译运行了,用的是iarwain的standalone(教程10stand alone & localization )的例子。
Orx的设计(纯个人看法)
说在Hello World前面的话:仅仅想学Orx使用的人完全可以忽略,只要做到Orx 的 Hello World会比较复杂的心理准备即可。以下仅仅解释为什么会这样。
在Orx中Hello World的例子已经算是很复杂了,同时也说明了作为一个有一切完备野心的游戏引擎Orx的复杂之处。即,为了让Orx尽量的做更多的工作,为了让更多的东西可配置,事实上,Orx很难简单的作为一个库来使用,比如,简单的用一条Print语句让Orx在屏幕上显示一个Hello World。更进一步说,你要么用Orx,要么不用,很难说,我就想要Orx的某一部分,比如,就用Orx的图形显示部分,其他的东西都不要,你很难做到。
从这点上来讲,事实上,Orx本身的设计是比较缺乏正交性的,也就是说内部各模块之间关联是比较紧密的,以各种方式耦合在一起。也许你仅仅调用了一条orxObject_CreateFromConfig API语句,然后Orx使用了配置模块,读取配置,然后使用io模块,读取材质文件,使用display,render模块,显示物体,使用物理模块,模拟物理,使用FX模块来完成你配置的特效,甚至同时还使用了animation模块来播放你配置的动画,并用声音模块播放声音。简单的说,我要想将整个orxObject_CreateFromConfig的调用流程全部走一次,可以看到几乎整个Orx...........你没有看错,我说的就是一个API调用。初学者往往会在这里懵掉。
从根本上来讲,问题的关键在于配置,因为从最开始,iarwain就打算将Orx做成数据驱动的(实际是config驱动的)游戏引擎,所以,必然的,一切可配置的东西就和配置耦合在一起了。然后,为了能够在配置中能够简单的描述,iarwain提供了一个非常高级的抽象,object,object能够表示上述几乎所有模块的配置,于是乎,object也陷进了强耦合性的深渊了。。。。。最后,也就形成了上面的情况,一个orxObject_CreateFromConfig调用,你实际可能是在调用整个Orx的各个模块。
不知道iarwain是否考虑了到了这一点,所以在Orx中提供了plugin的方案,使得你可以替换掉内部使用的一些东西,比如图形plugin,物理引擎plugin等等,但是,这还是不能改变其本质,你无法不使用配置和object。
但是,随着更进一步的了解Orx,和查看Orx的源代码,会发现Orx本身的设计会比你想象的要精妙。配置,问题的关键在于配置,iarwain想要配置主宰一切,就无法避开配置与一切关联的事实,然后,其使用了object来接管整个配置,也就接管了整个引擎。再然后,iarwain尽量的保持了下面的模块的正交性,虽然也许很多模块都会有一个XXX_CreateFromConfig接口,但是除了这个以外,大部分模块完全独立,由object来使用一切,然后由配置来控制object。其实也有一些例外,比如viewport,camera等,但是,总体效果上,Orx的引擎可以看成是大的层次结构 [ 配置 -> Object -> 其他模块 ],从这个角度上来看,Orx的分层次设计又是很优美的。
最后,从总体上来讲,作为一个游戏引擎,而不是一个游戏库来开发的Orx,自动的做了太多太多的工作,(Orx说他不喜欢重复的工作),于是乎,对于初学者来说,比如我,常常会碰到一个问题,也许是配置的问题,然后很难很难去发现和理解为什么出问题,再然后就非常痛苦的去看源代码,而这个过程,由于经过了太多层的转换,由于Orx做了太多的工作,会非常漫长。然而,当你熟悉这些配置后,你会发现,你能非常快的完成你的工作,非常的惬意。很多时候,一行代码+数行的配置,就能完成非常非常多的工作。也许,将来实现一个配置文件生成工具后,会更加惬意。
这就像你通过一个自动配置,然后看着华丽的自动化操作流水线自动的生产出了一台又一台异常华丽的汽车,最后你却发现汽车无法发动。你只能从流水线的设计上一个环节一个环节开始研究为什么。
而平时我们的工作常常是在完全手工的操作一个个流水线环节,当你焊接并安装上汽车的油箱的时候,你总会知道,新生产出来的汽车还是没有加油的。
Orx就像这个华丽的自动化操作流水线。。。。。。。。。。。。
INI配置语法
INI不是Json,不是XML,语法那个简单啊,用过Windows配置的,用过Linux众多软件配置的总会了解一些。但是iarwain在INI的基础上对INI进行了很多扩展。在Orx的WIKI上有关于Ini的详细的介绍 。基本上看过一遍就应该知道了。
应用程序的运行方式
在Orx中,可以通过将自己的应用程序编译成动态库,然后通过Orx加载的方式,来实现快速的开发,(这种方式现在似乎比较流行),因为这个过程省下了编写的应用与Orx库的链接过程,所以可以用于加快开发速度。(其实与Orx的链接时间实在也算不了多久,毕竟Orx其实很小,像OGRE那样的大工程才的确需要这样的机制)几乎所有的iarwain的教学例子都是如此。
与此对应的,将Orx的代码直接链接进自己的应用,那就叫standalone程序了。我个人比较习惯这样的开发方式,并且习惯将Orx的源码建立在同一个解决方案中,以方便查看和修改。前面提到的我建立好的工程即是如此。并且,在IPhone开发中,没得选择的,必须使用此方式。
配置,是Orx的很大一部分,这里不得不提及,Orx在启动时会自动的载入与应用程序名相同的ini,比如,运行orx.exe会自动载入orx.ini,按照我们的习惯,debug版本时,在应用程序后加d,编译成orxd.exe时,自动载入的是orxd.ini。此时,Orx config的include就能发挥作用了,一般的做法是只做一个实际的orx.ini配置,然后orxd.ini中include orx.ini。
另外,特别注意的是,这种载入是默认的操作,并且是必须的。虽然Orx中有API orxConfig_Load可以手动载入配置,但是因为Orx 的辅助函数orx_Execute,(一般的使用方法)在启动初始化各模块时就使用了配置的Display段的信息来创建窗体,而手动载入配置总是会晚于这个过程,所以在Orx中必须有默认的ini,并且,必须有合适的display字段和physics字段的配置,不然在debug模式下box2d会出现断言。(主要问题出在physics的初始化上),除非你自己写一个新的类似orx_Exccute的函数,自己手动处理主循环,各模块的初始化,显示的设置。个人感觉这是个bug。。。。。。。。已经在Orx的论坛上发帖询问了,看看再说。(BTW:由于iarwain如此的热心,你有任何疑问都可以在Orx的论坛上发帖问,几乎总是会得到回应,iarwain那是知无不言言无不尽啊。。。。。)
Hello World
在了解了这么多之后,总算可以开始学习怎么用Orx来显示Hello world了。要显示Hello World,首先需要创建出合适的窗体,并了解Orx中的一些主要配置。可以参考此WIKI 。
Display
display是其中最主要需要了解的。
[ Display]
Decoration = <bool> ;是否显示窗体的外观,比如标题,边框等。
FullScreen = <bool>
ScreenWidth = <int>
ScreenHeight = <int>
ScreenDepth = <nt>
Smoothing = <bool> ;是否扛锯齿
Title = <string>
VSync = <bool>
其他的都很好理解了。
其他辅助配置
[Render]
ShowFPS = true; NB: Displays current FPS in the top left corner of the screen;
简单的用于显示FPS。太方便了。。。。。。。。。。。我不知道在不同场合用不同的方法实现此功能多少次了,iarwain能将此功能整合进引擎,实在是善莫大焉。
[Clock]
MainClockFrequency = 20
只用于没有垂直同步的情况。不然一旦设置,会消耗大量的CPU,一般情况不要有此配置段即可。
有了上面这些,我们已经可以创建一个窗体了。。。。。。。
调用一条语句:
orx_Execute(argc, argv, Init, Run, Exit);
给出3个空的回调即可。。。。。。
我这里给其包装了一下,全部整合进一个单件的GameApp中。
全部源代码可以整合进一个文件中,也不大:
#include "orx.h"
#include <iostream>
class GameApp
{
public :
static orxSTATUS orxFASTCALL EventHandler(const orxEVENT *_pstEvent);
static orxSTATUS orxFASTCALL Init();
static void orxFASTCALL Exit();
static orxSTATUS orxFASTCALL Run();
GameApp() {};
~GameApp() {};
static GameApp* Instance() {
static GameApp instance;
return &instance;
}
private :
orxSTATUS InitGame();
};
// Init game function
orxSTATUS GameApp::InitGame()
{
orxSTATUS eResult = orxSTATUS_SUCCESS;
// Creates viewport
if ( orxViewport_CreateFromConfig("Viewport" ) == NULL ) {
eResult = orxSTATUS_FAILURE;
}
// Done!
return eResult;
}
// Event handler
orxSTATUS orxFASTCALL GameApp::EventHandler(const orxEVENT *_pstEvent)
{
// Done!
return orxSTATUS_SUCCESS;
}
// Init function
orxSTATUS GameApp::Init()
{
orxSTATUS eResult;
orxINPUT_TYPE eType;
orxENUM eID;
/* Gets input binding names */
orxInput_GetBinding("Quit" , 0 , &eType, &eID);
const orxSTRING zInputQuit = orxInput_GetBindingName(eType, eID);
// Logs
orxLOG(" /n - ' %s ' will exit from this tutorial"
" /n * The legend under the logo is always displayed in the current language" , zInputQuit );
orxLOG("Init() called!" );
// Inits our stand alone game
eResult = GameApp::Instance()->InitGame();
// Done!
return eResult;
}
// Exit function
void GameApp::Exit()
{
// Logs
orxLOG("Exit() called!" );
}
// Run function
orxSTATUS GameApp::Run()
{
orxSTATUS eResult = orxSTATUS_SUCCESS;
// Done!
return eResult;
}
// Main program function
int main(int argc, char **argv)
{
// Inits and runs orx using our self-defined functions
orx_Execute(argc, argv, GameApp::Init, GameApp::Run, GameApp::Exit);
// Done!
return EXIT_SUCCESS ;
}
#ifdef __orxMSVC__
// Here's an example for a console-less program under windows with visual studio
int WINAPI WinMain(HINSTANCE hInstance, HINSTANCE hPrevInstance, LPSTR lpCmdLine, int nCmdShow)
{
// Inits and executes orx
orx_WinExecute(GameApp::Init, GameApp::Run, GameApp::Exit);
// Done!
return EXIT_SUCCESS ;
}
#endif // __orxMSVC__
并且,封装后,使用起来就像传统的C++方式了,另外,还可以通过clock来添加Update函数,当然,这是后话。
并且,上面演示了不从命令行运行的方式,即开启宏__orxMSVC__ 的方式,此方式下,会失去命令行,作为发布。但是也失去了日志输出,所以推荐调试时还是有命令行的为好。
创建后的窗体能在左上角看到FPS的显示。
viewport
Orx中的viewport如同3D中的viewport概念,可以参考《Win32 OpenGL编程(10) 视口变换 》,Orx WIKI中的配置详细讲解 。
[ViewportTemplate]
BackgroundClear = <bool>
BackgroundColor = <vector>
Camera = CameraTemplate;
RelativePosition = left | right | top | bottom
Position = <vector>
RelativeSize = <vector>
Size = <vector>
ShaderList = ShaderTemplate1#ShaderTemplate2
Texture = path/to/TextureFile
同样的,也可以通过viewport来实现一屏的多显。达到《Win32 OpenGL编程(10) 视口变换 》中的效果,而且iarwain的官方教程中就有这样的例子。(例5 )
要想在屏幕上显示个什么东西,确定viewport是必须的,不然Orx不知道该在哪个位置显示,但是,实际的使用会更加简单,因为Orx中的配置都是有默认值的,比如viewport一般而言。可以使用默认值,也就是说,当前的全窗口作为viewport。后面会讲到一些更复杂的应用,这里暂时一笔带过吧,毕竟还是Hello World阶段。。。。。。。。。。简单的说,viewport就是描述了在什么地方显示图形的问题。
camera
[CameraTemplate]
FrustumHeight = <float>
FrustumWidth = <float>
FrustumNear = <float>
FrustumFar = <float>
Position = <vector>
Rotation = <float>
Zoom = <float>
Orx WIKI中的配置详细讲解 。
viewport配置中会绑定一个camera,此camera决定了前后剪裁面等信息(如上配置所示),因为Orx是2D引擎,事实上是没有使用透视投影的,Orx使用的是正投影。前后剪裁面的设定决定了视景体剪裁的范围,这些与一般的概念类似。不明白的推荐看看OpenGL相关的知识。简单的说就是在此范围外的东西根本就不会显示。这里Orx将一些3D概念引入了2D引擎,其实增加了一般人的理解负担,个人认为绝大部分情况,其实一般的2D游戏开发者可以暂时忽略这部分,然后稍微将视景体的前后剪裁平面调大点,平时设置Object的时候注意Z轴的坐标位置不要超过此区域即可。
其实简单的说,Camera描述了你想要从哪个位置观察viewport显示的图形,并且描述了你观察的范围。
有个图对于正交视景体的描述很有帮助,来自于红宝书的在线网页。可以看到,Camera的配置其实就是对应描述了下面图中的各个值。

特别需要提及的是,前后裁剪面是半开区间,也就是说,图形显示的范围事实满足此公式: near < pos <= far。特别特别注意,虽然远平面上的物体会被显示出来,但是近平面的是不会的!
一般时候,如下的配置就已经很合适了。
[Viewport]
Camera = Camera
BackgroundColor = (0, 0, 0)
[Camera]
; We use the same size for the camera than our display on screen so as to obtain a 1:1 ratio
FrustumWidth = @Display.ScreenWidth
FrustumHeight = @Display.ScreenHeight
FrustumNear = 0
FrustumFar = 2.0
Position = (0.0, 0.0, -1.0)
Zoom = 1.0
在上面的例子中,Camera的显示范围大小就是在Display中设置的屏幕大小,前后剪裁面分别是距离摄像头0, 2.0,这是个相对值,相对于摄像头的位置而言的Z轴, 也就是说,上面的配置中,因为Camera的位置是-1.0,所以,其实前后剪裁面的Z轴绝对位置是-1.0和1.0。 需要特别注意。 只要在设置object位置的时候,保证在此范围内,就没有问题。
Text显示
天哪,当我需要来讲解Orx的时候,我才发现其复杂性。。。。。。因为大量的东西可配置,所以大量的东西都需要配置,这是很郁闷的,事实上,也许说明了Orx还不够成熟,默认配置还不是足够的好。总算可以开始显示文字了,到这个部分也还不简单啊。一个Hello World需要下面3段配置。
[HelloWorld]
Graphic = HelloWorldGraphic
[HelloWorldGraphic]
Text = HelloWorldString
Color = (255.0, 0.0, 0.0)
[HelloWorldString]
String = "HelloWorld"
配置讲了那么多,其实整个的游戏代码可以非常少。。。。。。
真正需要的是在Init的时候用下面几行代码即可。
// Init game function
orxSTATUS GameApp::InitGame()
{
orxSTATUS eResult = orxSTATUS_SUCCESS;
// Creates viewport
if ( orxViewport_CreateFromConfig("Viewport" ) == NULL ) {
eResult = orxSTATUS_FAILURE;
}
if ( orxObject_CreateFromConfig("HelloWorld" ) == NULL ) {
eResult = orxSTATUS_FAILURE;
}
// Done!
return eResult;
}
orxViewport_CreateFromConfig 用于从配置中创建Viewport,orxObject_CreateFromConfig 用于从配置中创建Text。
至此,Hello World算是完成了.
全部源代码可以在http://code.google.com/p/jtianling/source/list?repo=orx-sample&r=hello_world浏览或clone后,update到tag hello_world

在Text的创建上面,我与iarwain沟通过,我认为仅仅是创建一个文字,这样的操作繁复了,三段配置其实大部分内容都是无用的,但是iarwain的意思是他是为了尽量维护text与Object的统一,如上所示,创建text的函数都是orxObject_CreateFromConfig ,这样Text就能使用额外的很多对Object使用的函数,比如Fx啥的。
不过,我还是觉得太麻烦了,当我用这样的方法创建了一个主菜单以后,更加如此觉得,我决定添加一个便利函数,来完成这样的工作,不过放到下一篇中吧。
小结
全文到此也算结束了,一个Hello World牵涉到的东西之多,也许让很多人望而却步,的确,Orx在最开始的配置上,有点过于繁复了,一方面是因为Orx需要将大量的配置放出来以方便配置,另一方面,又没有提供足够好的默认配置,使得一开始的配置较多,但是,反过来说,这些都是配置上的问题,你可以从一些教程的配置的基础上开始工作,代码量其实是非常小的,上述例子中还有几行代码,那都是因为我对Orx的封装,实际的代码也就两个API调用。至于用代码更加容易理解,还是用配置更加容易理解,那就是见仁见智的问题了,我个人其实是更倾向于代码更加容易理解的,但是配置总的来还是方便。
原创文章作者保留版权 转载请注明原作者 并给出链接
write by 九天雁翎(JTianLing) -- www.jtianling.com
阅读全文....
Orx不是一个非常成熟的引擎,我一直这样觉得,相对于很多成熟的引擎,Orx还有很多功能上的缺失,还缺少很多有用的游戏概念的添加,但是,我们能够看到作者iarwain的不懈努力。他曾经提到,他在Ubisoft工作之余,一边要带孩子,一边将其他所有的业余时间全部都投入到了Orx的开发中。。。。。而且,iarwain开发Orx,仅仅是for fun.....
在1.2版本中,iarwain添加了新的功能,在官网上如此描述“
custom bitmaps support and UTF-8 support.
”,呵呵,UTF-8
是个作者没有定在1.2版本Road map中的功能,仅仅是因为来自东亚(比如中国)人对Orx的增多的兴趣,而决定在新版本中添加的。。。。。^^
另外,虽然作者在最新的news中没有提及,但是我知道1.2版本的新的其他改动,对IPhone,IPad的支持,以及其他系统的版本从SFML库改到了SDL这个更为成熟,大家也更加熟悉的库。
这里顺便提及SFML与SDL的比较,不浪费任何有用的经验:)作为iarwain这样一个经验丰富的程序员,他对SFML与SDL的比较时,这样描述SFML,buggy,但是实现的特性更加多,可惜有很多是游戏引擎本身就会实现的,所以事实上多出的特性很多有重复了,由于使用C++及面向对象的方式提供接口,对于使用C++的人来说,会更加易于使用。。。。当然,buggy一词,完全的打消了我对SFML的兴趣。而SDL,提供的接口更加底层,效率更高,(因此,1.2版本的Orx效率也会更高),更加成熟,稳定。
阅读全文....
本来想问iarwain(Orx维护者)Orx
是啥意思,然后可以给他取个中文名,以利于在宣传。结果他说,means nothing............
Orx的名字来源于他老家的一个沼泽。。。。。。。还给我发了一张图片。至于为啥要用一个沼泽的名字给一个游戏引擎命名,他说,just like it.......看来还是很难适应外国人的思维。。。。。。。
就像我看firends里面成天oh my GOD,oh my GOD,oh.......my.......GOD的时候,真的与一个外国人沟通的时候,说了句oh my GOD,他还要说她是基督徒,希望我能说oh my 或者oh my goodness............无语了。

风景倒是不错。。。。。。。。不过我说,用沼泽给一款游戏引擎命名感觉比较怪,容易给人不好的联想,iarwain倒是没有反对。。。。。。废话嘛,用这个引擎就像进入了一个沼泽地一样,直接就陷进去了。。。。。要么就往好的方向想想?无法自拔?-_-!死路一条。
阅读全文....