博客的主题,插件基本恢复~~~因为这次有cPanel的帮助,效率高了很多,几个小时的时间,博客就恢复到丢失前的水平了,果然还是应该用这种强大的工具啊~~~用命令行折腾的其实也没有多么有趣,早就比不上以前自己用gcc和make的时代了,光是yum/apt-get install一下,也不见得有什么乐趣可言,还不如点鼠标........明天接着恢复一些内容~~~
写博客的孩纸真伤不起啊,把自己的业余时间全部都搭进去了......
阅读全文....
因为刚刚开始自己尝试建wp博客,买了VPS,并且用的月付费,结果因为上个月忘了付钱了,尽管我在发现博客停止的第二天就补上了钱,但是托管商已经直接把数据删了,所以完全无法恢复,这个太悲催了,最悲催的是,我前段时间在服务器面板上使用的备份功能被告知没有用,只能从服务器上的备份数据恢复,不能上传数据(我备份后下载回来的)恢复...........于是,重建博客吧.........
首先尝试用amazon ec2来搭建wordpress,上手还算比较容易,但是我发现amazon的RDS太贵了,折算到人民币要5K多一年,而且没有免费的一年试用,所以作罢。
然后不过这次不再使用VPS了,我发现我其实也不需要,以前想要VPS做一些服务器要做的事情,其实现在可以通过amazon ec2来完成了。让blog就是blog吧,这样买个虚拟空间也便宜,还能用cPanel....干什么都挺方便的,不要再自己折腾linux的配置了,呵呵,我发现我现在越来越懒于折腾了,难道是老了吗?曾经我认为人生在于折腾......
阅读全文....
最近除了编程相关的技术书籍, 也看了一些关于行业发展和企业管理的书籍, 创新者的窘境就是其中之一, 这本书很实在的为我进行了一些知识的梳理.
阅读全文....
只有偏执狂才能生存(一下以”偏执”来替代)一书听起来就像是某个大牛的布道式自传, 要告诉你需要怎么偏执才能生存, 自己又是怎么通过偏执成功的, 其实, 真正讲的是与战略转折点到来时, 企业的应对之道. 就像书上封面上写的那样: “战略转折点来的时候, 如果你不想被摧毁, 就只能快速反应, 适应, 并且改变. “
阅读全文....
Texture packer的确比Zwoptex更加强大,功能更多,跨平台,在使用cocos2d-x在win32下开发的时候,能够在win32下使用的优点就更加明显了。何况Zwoptex以前是完全免费的,在用户多了以后坑爹般的开始收费了,连个可用的免费版本都没有(只有自己保留的老版本可用),而Texture packer一直有可用的免费版本,虽然Pro版本贵的离谱(对于中国人来说,100多块钱的工具太贵了,但是对于美国人来说又很便宜)。另外,假如你是博客作者或者是框架开发者,可以向作者申请免费的license,我的确收到了。有意思的是,作者后来以做SEO为由,要求我添加以Sprite Sheet Maker为文字的链接,链接到他们网站,真让人感叹,天下没有免费的午餐啊~~~~
Texture packer的主界面如下:

1.Add Sprites
上图中的样子就是用Add sprite功能,添加了cocos2d的示例图片后的样子。texture packer能够自动的用较为优化的算法来排列图片,使得占用空间尽量的少,作为初级版本,没有一些包括裁剪在内的高级功能(在强行使用高级功能后,会有提示,也可以导出图片,但是会随机在某些图片上印上一些英文文字)
2.设置导出文件的位置

这个位置是一个绝对位置,此时可以保存一份texture packer的工程。这个工程会记录这个导出的位置。有一点用户体验非常好的地方是设置了plist的位置后,texture的为止texture packer会自动生成一个。
3.导出
点击publish按钮即可。将来在原始图片更改的时候,直接载入这个工程,然后也只需要再次点击public按钮即可,会同时生成plist和texture文件。相当易用。
Enable auto alias非常有用,可以将相同的图片自动合并,对于三维导出的序列帧和flash自动导出的序列帧动画,常常可以节省很多空间。
到目前为止,这已经很强大了。但是Texture packer的强大不仅如此,手工编辑再方便,也不如自动化来的快~~~~
Texture packer在安装后,在安装目录下(windows)会有一个叫texture packer的可运行文件,直接将刚才生成的tps文件作为参数传进去,就能自动的生成~~~再配合VS或者XCode的工程配置,完全可以做到生成程序的时候对texture的全自动化处理。(不过这个需要pro的license)
4.程序中的使用
先通过以下接口预加载
void CCSpriteFrameCache::addSpriteFramesWithFile(const char *pszPlist)
然后通过以下接口使用:
CCSpriteFrame* CCSpriteFrameCache::spriteFrameByName(const char *pszName)
CCSprite* CCSpriteFrameCache::createSpriteWithFrameName(const char *pszName)
CCSpriteFrameCache本身是个单件。
阅读全文....
用一个周末总算在ubuntu下把www.jtianling.com博客搭建好了,这里分享一些不成熟的经验。
准备工作
安装wordpress前需要安装的软件如下:
1.apache2,这个不用说了,没有apache就没有http服务器啊。
apt-get install apache2
2.php5,wordpress是用php写的
apt-get install libapache2-mod-php5 php5
3.mysql,wordpress以mysql为标准的数据库
apt-get install mysql-server-5.0 mysql-common mysql-admin php5-mysql
4.额外的东西,比如phpmyadmin,用于方便管理mysql,比如unzip,用于解压zip包。
大部分情况下,以上软件的安装只需要用apt-get install就能简单的安装。
用
/etc/init.d/apache2 restart
来重启apache服务器,基本上以上服务就可用了。
apache mod加载
可以通过
ls /etc/apache2/mods-enabled
来查看已经加载的apache mod,
通过
ls /etc/apache2/mods-available/
来查看安装了但是没有加载的模块。
假如没有加载好的话,可以通过a2enmod 加载。比如加载php模块。
a2enmod php5
加载后,需要重新启动apache。
phpmyadmin与mysql的配置
需要注意一点,在mysql刚刚安装好的时候,密码为空,而phpmyadmin偏偏不允许空密码,于是矛盾就产生了,也就是你第一次时没法直接就用phpmyadmin管理mysql服务器。
解决办法:
在phpmyadmin的配置
/etc/phpmyadmin/config.inc.php
中找到并取消调AllowNoPassword=TRUE一行前面的注释。
登录后,再修改密码,为了安全,最好记得回来再次注释调这一行。
在phpmyadmin为wordpress建立一个数据库,可以任意取名,默认的wordpress以wordpress命名数据库,数据库中以wp_开头建立表格。
安装wordpress
安装wordpress再简单不过了,你可以直接apt-get install一个,然后通过ln链接/share/wordpress到/var/www目录即可。不过这个一般是英文版,而且版本较老。
这里我用http://cn.wordpress.org/这里的中文版本,最新版本的下载地址,可以先下载在本地,然后通过ssh或者ftp传到服务器,也可以通过wget直接在服务器端下载,这个自己选择。
ssh传文件:
参考:http://bingu.net/653/howto-use-ssh-upload-and-download-files/
apt-get install lrzsz
安装rz,sz命令。
使用SecureCRT工具,登录后,使用rz传文件到服务器,sz从服务器传文件到本地。(默认存在我的文档)
wget下载:
这个就更加简单了,
apt-get install wget
然后直接wget file_link,就能直接下载地址指定的文件到服务器。
ftp需要配置ftp服务器,这个先不谈了。不管用什么办法,把http://cn.wordpress.org/wordpress-3.2.1-zh_CN.zip这个文件弄到服务器后,用unzip命令解压一份,然后直接mv到/var/www下,假如你愿意将整个apache都作为wordpress 博客(即apache的主目录),那么就直接将所有内容都放到www目录下,不然的话,可以放到/var/www/blog下。
然后通过
chmod -R 777 /var/www/
修改权限(上面操作不够安全)
也可以尝试通过
chown -R www-data:www-data /var/www
来修改文件本身所属的组和用户(我没有实验该操作)
解压后,wordpress目录还没有wp-config.php配置文件,一种方法是直接用wp-config-sample.php修改成wp-config.php,见此文档。
事实上在此时直接用浏览器访问wordpress所在的地址,就能有自动安装的配置页面引导安装,如下图:

这个非常简单,配置好mysql的数据库名,用户名,密码等信息,wordpress的用户名,密码即可。
然后,登录后即可见到wordpress的管理页面。

此时说明安装已经成功了,直接到你配置的地址去看看效果吧,wordpress默认给你建立了一个博客文章,一个页面。
配置及美化
wordpress的安装别提有多简单了,根本不费时间,但是实际上,为了让日志www.jtianling.com正常工作,用了我几乎整整一个周末,原因就在于wordpress虽然强大,但是强大在可配置性强,所以我用了很多时间找合适的主题,插件等来合理的搭配,并取得较好的效果。(目前我也实在不想再在blog的效果上再花太多时间了~~~其实我最喜欢的是可能吧的主题,但是好像没地儿找去...)
主题:
我很喜欢coolshell.cn,于是找到了酷壳的主题,主题的名字叫做inove。
并且inove主题的主题选项中,附带Feed配置,页面上也有个较为符合中国人习惯的RSS按钮。
还附带Google analytics的代码输入地址,非常方便。
插件:
酷壳无私的介绍了其博客使用的插件,因为博客的类型类似,也为了节省时间,就尝试了几个他列出的插件:
其中Akismet,因为用户不够多,还没有用上 。
All in One SEO Pack 不知道用了有什么用,看不到明显的效果。
Google XML Sitemaps没有兴趣使用。
WP Super Cache,也没有感觉到用途。
SyntaxHighlighter Evolved,安装了,也还没有使用......
倒是发现了其他几个插件的好用之处:
Faster Image Insert - 批量图片插入插件,非常好用。
WP-PostRatings - 下载地址。评分插件,我才不管IE浏览器是否能看呢,我的读者里面有用IE浏览器的吗?
插件开启使用后,需要进行一定的配置。
在single的页面,插入
<?php if(function_exists('the_ratings')) { the_ratings(); } ?>
到
<?php include('templates/comments.php'); ?>
之前,也就是放在评论之前。
在index的页面配置文件,插入到
<div id="pagenavi">
之前,也就是页面浏览之前。
这个也可以自己把握。
日志自动截断 - 自动截断日志文字的插件的中文版,使用此插件后,撰写日志时无需再加入more标签进行文字截断操作。采用UTF-8模式截取,中文无乱码。这个插件是为了达到coolshell那种首页只显示文章一部分内容而需要的,实际使用效果不错。
feeds:
参考:http://codex.wordpress.org/WordPress_Feeds
最后我用了
http://www.jtianling.com/feed=rss2
这个,然后用域名
http://feed.jtianling.com转向支持,作为永久的feed地址。
字体:
参考:http://www.qiyecao.org/wordpress/wordpress-fontstyle-setting.html
简单的说是,
font-family:宋体,微软雅黑,Arial,Verdana,arial,serif;
font-size自己进行合适的修改,一般来说,普通的12px改为14px,其他的酌情放大处理。原因在于主题是英文的,而英文一般用12px,中文用12px偏小,用14px较为合适。
备份
好不容易搞了这么多东西,不备份一下心里不踏实啊:
tar czvf www.tar /var/www
然后用sz传回到本地保存起来
最后的样子,也就是本博客的样子了~~~~
阅读全文....
在用Qt的时候,自然是使用Qt的解决方案,简单易用,参考《字符串的多国语言支持解决方案 Qt篇》。
在不需要跨平台开发iPhone的应用时,自然使用iOS提供的多国语言支持解决方案
但是,不能用Qt,也不是开发纯iOS应用的时候呢?那就只能自己想个办法解决这个问题了。
根据实际情况,该解决方案需要符合下面的条件:
1.代码中使用时,不应该有太多额外的负担,不降低代码的可读性
2.不用单独的工具也能使用
第一条很好解释,假如为了多国语言而浪费太多的精力实在不值得,所以这里放弃更加高效的int编码索引字符串的方式,那种方式的确更加高效,但是代码中需要使用宏/常量来索引字符串。
第二条就完全处于开发简单的考虑,不要神马分析,生成等乱七八糟的东西,所以也不会如很多解决方案一样使用啥excel,然后通过工具解析成二进制的格式,然后程序中去解析二进制数据,那不是自虐吗?
那么方案其实就慢慢出来了,以文本配置来存储多国语言的文字,一种语言一个文件。在文本配置的格式选择上,使用json。用字符串Key来索引字符串,索引失败时,就直接显示Key字符串。
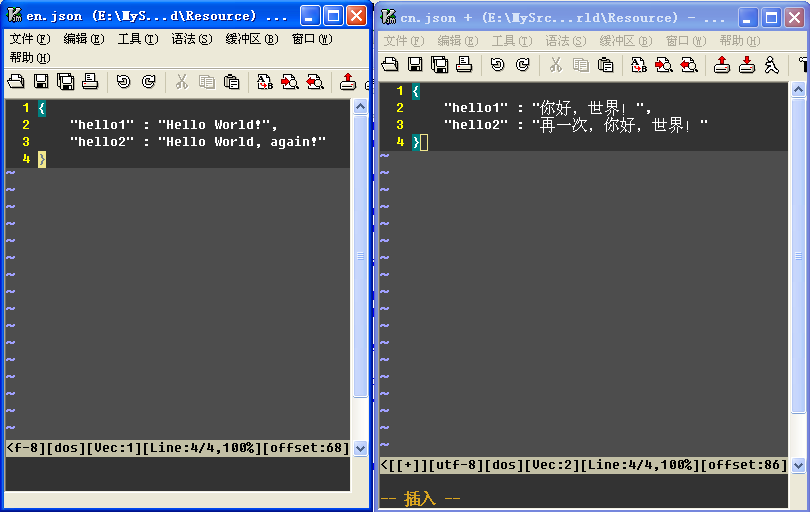
首先,json的格式就是最简单的以key为索引的字符串组合,比如,我现在建立一个en.json表示英文,一个cn.json表示中文。
然后实现如下StringManager,该类为Singleton:(用jsoncpp为json的解析库)
头文件:
class StringManager : public Singleton<StringManager>
{
public:
bool Init(const char* filename);
std::string GetLocalizedString(const char* key);
private:
Json::Value string_map_;
};
部分实现:
bool StringManager::Init( const char* filename ) {
if ( !ReadJsonFromFile(filename, string_map_) ) {
return false;
}
return true;
}
std::string StringManager::GetLocalizedString( const char* key ) {
if (string_map_.isMember(key)) {
return string_map_[key].asString();
}
else {
return std::string(key); // 当查找不到key时,直接显示key
}
}
一般情况下,直接通过StringManager的GetLocalizedString函数来获取字符串即可,为了更加简单,定义如下的宏:
#define LS(key) StringManager::Instance()->GetLocalizedString(key)
使用时,先需要以字符串的配置文件名初始化StringManager,读取字符串信息。以后,使用起来就和Qt中很类似了。即以LS()方式包含你需要显示的文字。
比如下面这样,为了减少其他无关信息,就没有添加显示部分的代码了:
在以上的例子中,我是使用utf8来保存多国语言,假如你是使用UTF16的话,请将相应的字符串表示改为宽字节即可。
小结:
因为没有额外的工具支持,这样的方式也许没有qt,iOS里面那么便捷,但是实现简单,容易理解,同时使用起来也足够的方便,最最重要的是,除了C++编译器,这套方案不依赖于平台或者其他神马东西,你随时随地都可以使用。(本例中用jsoncpp解析json,jsoncpp也仅依赖C++编译器存在)
阅读全文....
最近比较懒,公司的事情忙完后,在家也就是看看《Game Engine Architecture》,好久没有写博客了,总算遭到报应了,昨晚腹泻,发烧,冷汗,今天一天班都没上,于是,闲话少说,还是写篇博客吧.......
在不久以前,软件还是由一帮根本不知道世界上存在其他语言的美国人制作的,那时候他们只用ASCII编码去写软件。然后当他们发现世界上还有其他语种的人也需要使用软件,并且也有很大市场以后,出现了多字节的解决方案来解决字符串的国际化问题,但是那是段相当恐怖的日子。再然后,我们有了Unicode,一切就简单了很多。
假如一个软件只支持中文,那么简单的使用unicode的中文去表示UI中的所有字符串就好了,但是要支持多国语言呢?具体说来怎么样才能方便的在不同语言中进行切换呢?
Qt的强大程度在很多方面都远超一个framework应该呆的范围,基本上是一个强大的跨平台解决方案,其中,对于多国语言,Qt的解决方案也是我见过的最好的。
对于Qt的字符串来说,分成两种情况:
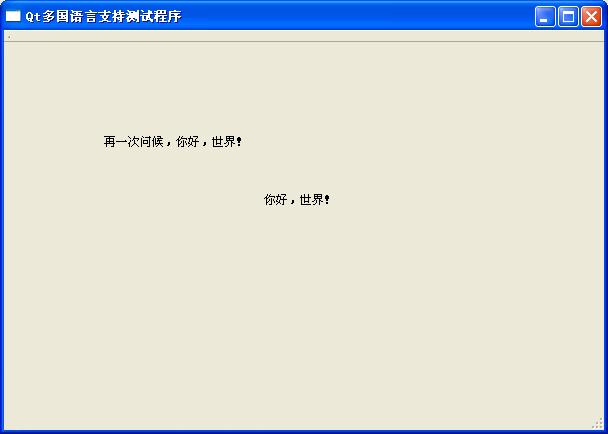
1.在Qt Designer中拖放控件时,控件上的字符串。比如,我摆一个label上去,叫做hello world。注意的是需要在translatable属性上打勾(默认就是打勾的),表示可以翻译。
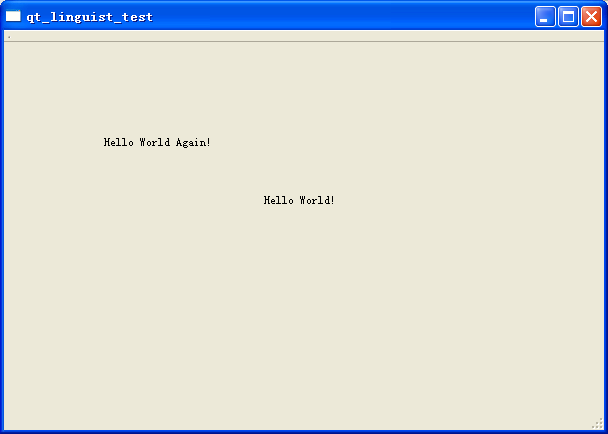
2.在代码里面直接指定的字符串,需要用tr()包含该字符串。比如手动创建一个label,显示Hello World Again!
QLabel *label = new QLabel(this);
label->setText(tr("Hello World Again!"));
label->setGeometry(100, 100, 200, 25);
此时整体程序的显示内容如下:
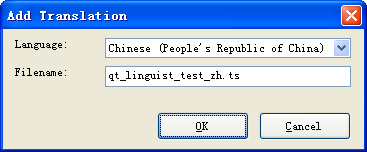
此时,通过Qt菜单中的(用了qt的Qt Visual Studio Add-in)的Create New Tranlation File,
比如,这里我建了一个中文的文件,叫做qt_linguist_test_zh.ts,在VS中双击此程序,会用Qt Linguist打开此文件,接下来的就简单了:
分别在左边选择字符串所在的context,然后在Strings里面会列出所有可以进行翻译的字符串,在Sources and Forms中甚至还能显示出上下文,帮助你进行翻译。
在下面的translation中写上你想翻译的内容,保存好。
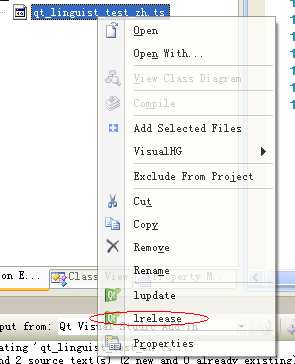
在VS中,用lrelease解析(编译?)此文件
此时,可以在工程目录下看到一个叫做qt_linguist_test_zh.qm的文件,就是刚刚生成的文件。在代码中使用该多国语言的文件实在是简单了,只需要下面几行代码:
QApplication app(argc, argv);
QTranslator translator;
translator.load("qt_linguist_test_zh.qm");
app.installTranslator(&translator);
从此以后,所有的字符串都会按照你翻译过的来显示:
小结:
Qt的多国语言支持主要来源于Qt Linguist这个翻译程序,按照Qt本身的设计,这个程序甚至是交由翻译人员去使用的,和程序员无关,程序方面只需要记得在代码里面的字符串加tr()就行,然后通过lupdate(在上面的例子中用Qt Visual Studio Add-in来完成了)去提取代码中所有可以翻译的字符串,生成ts文件,然后把ts文件交给翻译人员使用即可。其方便性在于不仅是程序员使用方便,还从软件开发流程上让各个环节都有合适易用的工具去高效的完成各自工作......作为程序员,开发一个Qt的多国语言支持的软件几乎没有任何额外的负担..............
阅读全文....
write by 九天雁翎(JTianLing) -- blog.jtianling.com
新浪微博 -- 讨论新闻组 -- 代码库 -- 豆瓣
前言
作为系列的第一篇,如同往常一样唠叨几句吧,好久不写这种单纯语言相关的(特别是C++)文章了,因为慢慢觉得这些东西自己学学就OK,实际写出来的价值有限,因为思想少,技巧/知识多。因为前段时间做了半年多的Object C和JAVA了,并且C++ 0x标准就要出来了,语言改变还挺大,趁这个节骨眼,顺便再回头学习/总结一些我感兴趣的C++知识吧,不过应该持续时间不会太长,这个系列也不会太长,因为语言已经不是我关注的重点~~~~
Google的C++ Style Guide是我自己写东西的时候遵循的C++代码风格规范,前段时间看到李开复说他才发现Google的C++规范已经公开了,说这是世界上最好的C++规范,我感到很惊讶,因为N年前这个规范已经就公开了-_-!事实上,Google的 C++ Style Guide远不仅是一个传统意义上的代码书写风格指导,对于C++的方方面面做出了Google的解释和使用建议,包括每个规则给出时,较为详细的讲了这个规则好的一面和不好的一面,最最激进的规则甚至有禁用C++的异常,以及除了Google规范的Interface作为基类外,禁用多重继承,在绝大部分情况下禁用默认参数等内容。在很大程度上,Google是想把C++打造成效率高的JAVA来使用~~~~
Google的C++ Style Guide有关于Boost的一节,允许使用的Boost库如下:
Call Traits from boost/call_traits.hpp
Compressed Pair from boost/compressed_pair.hpp
Pointer Container from boost/ptr_container except serialization and wrappers for containers not in the C++03 standard (ptr_circular_buffer.hpp and ptr_unordered*)
Array from boost/array.hpp
The Boost Graph Library (BGL) from boost/graph, except serialization (adj_list_serialize.hpp) and parallel/distributed algorithms and data structures (boost/graph/parallel/* andboost/graph/distributed/*).
Property Map from boost/property_map, except parallel/distributed property maps (boost/property_map/parallel/*).
The part of Iterator that deals with defining iterators: boost/iterator/iterator_adaptor.hpp, boost/iterator/iterator_facade.hpp, and boost/function_output_iterator.hpp
对此我感到比较惊讶,除了Array没啥好疑问的以外,我发现一些的确很好用的Boost库Google并不允许使用,比如boost::bind, boost::function, boost::lambda 等,这个我不理解~~~~而Google提及的几个Boost库,除了Array很简单实用,BGL是一个数据结构和算法的扩充库,以前没有接触不奇怪外,其他的东西我发现自己竟然没有太接触过,作为自认为C++学习已经接近语言律师的我情何以堪-_-!~~~~~
因为很多时候,一个Boost库就代表着一个C++的缺陷的补救,因为即使最后不用Boost库,了解一下对于怎么正确的使用C++还是有很大帮助的。特作此系列。
1.Call Traits from boost/call_traits.hpp
先谈谈什么是Traits,BS的解释如下:
Think of a trait as a small object whose main purpose is to carry information used by another object or algorithm to determine "policy" or "implementation details". - Bjarne Stroustrup
可以参考这里。所谓Call Traits就是调用时需要的Traits。 Call Traits中文文档看下基本就明白啥意思了。我感觉最大的作用是在写模版类/模版函数传递参数时,保证没有“引用的引用”的情况发生,并且总以最高效的形式传递参数。所谓的最高效形式的规则类似JAVA,(仅仅是类似)即原生的类型就使用传值方式,对象就采用传引用方式。这里有个中文的例子。
正常情况下,一个函数在C++中要么以传值方式传递参数,要么以传引用的方式传递,没法两者兼得:
template <class T>
class TestClass {
public:
TestClass(T value) {
}
TestClass(const T& value) {
}
T value_;
};
在使用时会报错:
error C2668: 'TestClass<T>::TestClass' : ambiguous call to overloaded function
因为C++的函数重载规则并没有规定在这种情况下会调用哪一个函数,导致二义性。
使用Call_Traits的param_type作为参数类型时,以下例子:
int g_i = 0;
class PrintClass {
public:
PrintClass() {
printf("PrintClass created");
++g_i;
}
};
template <class T>
class TestClass {
public:
TestClass(typename boost::call_traits<T>::param_type value) : value_(value){
}
T value_;
};
TestClass<int> test(10);
PrintClass printClass;
TestClass<PrintClass> testPrintClass(printClass);
g_i会等于1,实际因为传递的typename boost::call_traits<T>::param_type value在参数类型是PrintClass(一个对象)时,传递的是引用。同时,我没有想到更好的办法去验证在传递的参数是int类型时,的确是通过时传值。这样说来就很有意思了,因为即使我们在使用模版时函数全部通过传值方式来设计,会在T是对象时导致很大的额外开销,我们全部通过const T&的方式来传递参数就好了,就算是原生类型,这种额外开销还是小到足够忽略不计的,只是,boost库的制作者觉得这样还是不够完美?
同时,Call Traits还解决一个问题,那就是"引用的引用",比如上例中T为T&时的情况..........函数参数假如是通过传递引用的方式的话,const T&的参数,T又等于T&,那么就是const T&&了,C++中没有引用的引用这种东西的存在(只有指针的指针),事实上,Call Traits给函数的调用和参数的类型有完整的一套解决方案,如boost文档中的example 1:
template <class T>
struct contained
{
// define our typedefs first, arrays are stored by value
// so value_type is not the same as result_type:
typedef typename boost::call_traits<T>::param_type param_type;
typedef typename boost::call_traits<T>::reference reference;
typedef typename boost::call_traits<T>::const_reference const_reference;
typedef T value_type;
typedef typename boost::call_traits<T>::value_type result_type;
// stored value:
value_type v_;
// constructors:
contained() {}
contained(param_type p) : v_(p){}
// return byval:
result_type value() { return v_; }
// return by_ref:
reference get() { return v_; }
const_reference const_get()const { return v_; }
// pass value:
void call(param_type p){}
};
这里正好找到一个很perfect的文章,简单的说就是当pair中某个类是空类时,compressed Pair比std中的pair会更省一些空间(1个字节...........),我几乎没有想到我实际工作中有什么对空间要求非常高并且还会使用pair的情况.................这也就是compressed_pair的尴尬之处了。可以稍微提及的是,看看compressed pair的定义,就能看到call traits的使用:
template <class T1, class T2>
class compressed_pair
{
public:
typedef T1 first_type;
typedef T2 second_type;
typedef typename call_traits<first_type>::param_type first_param_type;
typedef typename call_traits<second_type>::param_type second_param_type;
typedef typename call_traits<first_type>::reference first_reference;
typedef typename call_traits<second_type>::reference second_reference;
typedef typename call_traits<first_type>::const_reference first_const_reference;
typedef typename call_traits<second_type>::const_reference second_const_reference;
compressed_pair() : base() {}
compressed_pair(first_param_type x, second_param_type y);
explicit compressed_pair(first_param_type x);
explicit compressed_pair(second_param_type y);
compressed_pair& operator=(const compressed_pair&);
first_reference first();
first_const_reference first() const;
second_reference second();
second_const_reference second() const;
void swap(compressed_pair& y);
};
说实话,虽然逻辑上感觉完美了,但是代码上还真是累赘...........typedef简直就是C++强类型+类型定义复杂最大的补丁工具.............但是总的来说compress pair是很简单的东西,不多讲。
3.Array from boost/array.hpp
Array也是最简单的boost库使用类之一了,用于以最小性能损失替代原生C语言数组,并且像vector一样,提供使用的函数和合理的封装(STL提供的vector因为是变长数组,还是有一定的性能损失)感觉不是非常非常效率要求的工程,可以将所有的C语言数组都用Array来代替,意义更加明确,迭代器使用也会更加方便,容器的使用语法也更加统一。另外,C++0X已经确定添加array库,array将来就是未来的标准库,可以较为放心的使用,并且即使使用了,也是可维护的代码(即使将来使用C++0X时也是一样)。
操作示例:
boost::array<int, 100> intArray;
intArray.fill(10);
for (boost::array<int, 100>::iterator it = intArray.begin();
it != intArray.end(); ++it) {
*it = 20;
}
小结:
基本上,
1.call traits是看需求了,假如你实现模板库有需要才使用,不要因为真的仅仅为了一个函数的参数调用能够以最优化的方式进行而去使用call traits。
2.comress pair是我不太推荐使用(为了一点点空间,而增加理解的难度不值,推荐的方式是将来STL的pair实现就是compress pair)
3.array是推荐使用
原则是,有利于抽象和源代码易读性的用,否则不用.............
阅读全文....
很久没有写博客了.........今天发现访问量已经超过80W了,很感叹,今天不谈技术,谈谈技术外的娱乐~~~~
在Google I/O刚放出Google Music Beta就赶快冒充美国IP去申请了邀请码,在前两周很幸运的收到了邀请被确认的消息,第一时间开始逐步的把听音乐的习惯迁移到Google Music Beta上。发现虽然Google号称自己在Google Music Beta上使用了Flash技术并且没有提供iOS版本的App,导致大部分人感叹Google故意以此来限制Google Music Beta在iOS设备上的使用,说实话,这是以小人之心度君子之腹了~~~~因为就我实际的使用发现,不仅iPad可以直接通过网页形式使用Google Music Beta,iPod也行(虽然屏幕实在太小,操作不方便),只是播放的时候点一次播放不行,需要暂停了再点播放,就能正常播放了。
Google Music Beta最大的特点就是在云端,而且全都是自己上传的音乐(虽然没有码率提升功能,但是事实上也算是可以完全控制),但是Google Music还是有一些缺陷:
其一:支持的音频格式实在有限,特别是不支持无损格式,比如ape。很多无损控估计会很郁闷。
其二:没有歌词,对于中国人,因为有英文歌的存在,估计很多人会像我一样希望有歌词,当然,即使不听英文歌,你听周杰伦歌的时候,歌词也是需要的~~~~~~
然后英文歌的播放使用一如既往的没有问题,但是中文歌的歌名/歌手名显示碰到一个很大的问题,有时候会是乱码,在网上查了查,发现很多人有类似的问题,但是却都是提出Google Music Beta不支持中文,没有任何解决方案,对此我较为不爽,所以尝试自己找找解决方案,不就是编码问题嘛,我感觉Google怎么说也得支持下某种形式的Unicode吧.
于是....尝试开始.....
Windows下:
QQ Music:
交互设计非常好,用户界面感觉很棒,下载方便,音乐库音乐丰富,音乐的码率较高,也有关于mp3 tag的设置,可以写入ID3v1 与/或 ID3v2,还可以设置ID3v2的编码为ISO-8859-1或者UTF16, ID3v1乱码,ID3v2 + ISO-8859-1乱码,尝试设置ID3v2 + UTF16后在公司的Windows7的机器上,Google Music Beta的网页版本中文显示正常,但是ipad上和Android上的Google Music中文不能正确显示.(此时怀疑Google Music Beta在Android上和iPad上使用的编码是utf-8?)另外,对于QQ Music我还有个不满,那就是专辑的tag信息经常是啥 "20xx年xx月新歌速递",不知道在腾讯的QQ Music的编辑是怎么想的......简直是为了推广逆天行事啊~~~~~~~或者是因为程序的原因?不通过修改弄成一个专辑,不能合适的通过一个专辑页面发布?总之这样的行为是大大破坏的其歌曲信息的正确性,完整性,非常不方便用户管理.但是最最奇特的是,回到家中,使用Windows XP的QQ Music,虽然同样的是设置为UTF16的编码,但是上传后显示竟然一切正常了,不知何解。
千千静听:
老牌的音乐播放器,原来本地听音乐的时候为了更好的歌词效果舍弃了Winamp然后选择了他.放弃千千静听的最大原因是它被百度收购了,然后在尝试向网络播放器转型的过程中太乱了,广告一堆一堆,看的我非常烦躁,一个播放器不老实的在后台呆着,你老给我蹦窗口,谁受得了啊,就像当年卸载搜狗输入法一下,碰到这种情况,毫不犹豫的卸掉,再也不想用.正好碰到1g1g和Google Music(cn版)慢慢就习惯了在网上听了.告别千千静听这么久了,这次因为Google Music Beta的问题,才特别的回来看看.发现千千静听老牌就是老牌,虽然下载不是很方便,音乐库的界面排的太挤,比较丑陋,本地播放器的现在的默认界面颜色也太惨白(甚至还不如以前我用的时候好看),但是关键是,从音乐库下载音乐回来后,发现在Google Music Beta中的乱码问题解决了,在Android和iPad上都能正确显示~~~~~老牌的东西果然考虑问题就和新加入的小弟小妹不一样,就是能解决问题........千千静听的Tag编辑一栏有个高级选项,可以转换内码.(这点也体现出了千千静听耕耘音乐软件多年的技术积累及软件功能积累,当年我喜欢千千静听的原因之一就是编辑MP3的信息非常方便,甚至有自动从文件名识别等批量编辑方式)首先我看了一下能够正确显示中文的音乐文件的内码,竟然显示是GBK,这个我很惊讶......
Mac OS X下:
沒有特別好用的本地网络播放器程序,所以一般用网页版本的替代品.
Google Music (cn版本)
因为全是正版,刚出来的时候很喜欢用,可以较为方便的下载回来,而且tag信息很全,只是后来好像一直没有啥新功能加入,在Windows下一般就用QQ Music了,只是在Mac下才使用,这次使用发现果然是Google自家的东西,下载回来不仅信息挺全,上传到Google Music Beta后,在Android和iPad上看也一切正常~~~~看来Mac下该用什么没啥好试的了,因为也不用改.
最后,一些跑题的尝试:
尝试在QQ Music中下载一个音乐回来,(已经设定为UTF16的编码方式保存tag)然后在千千静听中编辑信息,高级选项中编码显示也是GBK后,再上传.发现显示正确......这点我非常无语,也就是说,因为QQ Music在Windows7上确实是以UTF16的这种Unicode方式保存Tag信息,在Google Music Beta中无法正确显示中文,而在WindowsXP上虽然选择的是UTF16,但是实际还是GBK编码,因为Google Music Beta接受显示中文的编码是GBK~~~~集体晕倒去吧.....看来用unicode生,不用unicode死这个原则碰到Google这种家伙不好用了.......加上Google Music (cn版本)下载回来的音乐文件也能正确显示的事实,是不是就是因为Google Music (cn版本)的tag用了GBK编码,所以Google Music Beta为了支持自家产品,所以做出这么奇怪的设计啊?
最后想到在Windows7下,假如不想改变使用QQ Music的习惯,又想保持Google Music不乱码,我发现也有方法了,那就是用QQ Music下载,然后用千千静听转码~~~~因为千千静听选项中有个自动监视文件夹改变的功能,所以相对来说,只要将其开在后台,就能自动的将QQ Music新下载的歌曲添加到播放列表,然后再设置Google Music Manager为每隔一段时间添加歌曲的方式(不然的话感觉在还在下载的时候就已经开始上传了),这种方案已经基本能解决问题了~~就是额外的多开了千千静听,感觉挺累赘,还要接受他的弹窗....习惯使用千千静听的童鞋那就爽了,继续用千千静听就好了~~~~当然,假如有天QQ Music能够解决此问题就更加完美了.
以上研究的最大问题在于关于Windows7部分乱码的原因和解决方案还有待回到公司检验,现在周末在家只有WindowsXP的机器。
阅读全文....